Kazutaka Furuse*,
Kazunori Yamaguchi**,
Hiroyuki Kitagawa, Nobuo Ohbo &
Yuzura Fujiwara
Institute of Electronics & Information Science
University of Tsukuba
Tsukuba-Shi, Ibaraki 305, Japan
Abstract: This paper describes the mechanism for implementing the data type indepen-dence of access method modules in the extensible DBMS MODUS. This dependency makes users' work to implement access method modules smaller. In MODUS, since every access method module has nothing to do with any data types, users do not have to write codes sensitive to each data type. Furthermore, when new data types are introduced in the future, users do not have to modify previously written access method modules.
Recently, the area of database applications is widely spreading, and for supporting non-traditional database applications (such as engineering design and mage/boice application), index mechanisms have been reported (Samet, 1989). For example, R-tree (Guttman, 1984; Sellis et al, 1987) whish is a hierarchical file structure similar to B-tree, was proposed an effective access method for storing and retrieving spatial (or multi-dimensional) data objects. To exploit such new index mechanisms, database management systems (DBMSs), which have the functionality of embedding new index mechanisms a posterior (Carey & DeWitt, September 1986; Furuse et al, December 1990) have been developed. These systems are called extensible DBMSs (Carey & Haas, December 1990).
In the extensible DBMSs, each index mechanism is implemented as an access method module. The access method modules implemented by users can be embedded into the systems and they are used in the course of query processing. Thus, with the extension by user defined access method modules, it is possible to construct DBMSs with new index mechanisms.
However, in the extensible DBMSs currently available, it is impossible to implement access method modules independently of data types. That is to say, each index mechanism can be used only for indexing data objects of one data type. For practical use, it is desirable that the extensible DBMSs provide the facility to implement access method modules without data type dependency. For example, if an R-tree access method module is implemented independently of data types, this module can be used to index both two-dimensional data objects and three-dimensional data objects without any modification. Furthermore, even inf a new data type is defined afterwards, users are not required to implement a new R-tree access method module specific to that data type. To make this possible, in the extensible DBMSs, the facility of data type management and the facility of indexing must be implemented independently of each other. In other words, these two facilities should be orthogonal.
To achieve this goal, in the extensible DBMS MODUS (Yu, 1990; Furuse et al, December 1990), data types and access methods are defined and managed separately. In MODUS, the access method modules embedded into the system are managed by a component of MODUS called access method manager. In MODUS, data types are also implemented in modules. They are called data type modules. Each data type is defined in a data type module. The data type modules are managed by a component of MODUS called data type manager.
The major advantage of MODUS in comparison with other extensible DBMSs is that user defined modules are highly reusable. This is because data type modules and access method modules are defined independently of each other. By coupling a data type module and an access method module, it is possible to provide a facility of indexing of the access method for that data type. Users are not required to write data type sensitive codes in their own access method modules. Moreover, no modification is required when some data types are introduced afterwards. In this paper, we describe the mechanism of MODUS which implements the independence between data type manage-ment and indexing facility. We also describe the mechanism of query processing using some data type modules and some access method modules.
The remainder of this paper is composed as follows: Section 2 describes the architecture of MODUS. Section 3 describes the mechanism of extension in MODUS with some simple examples. Finally, in Section 4, we summarize this paper and discuss the remaining problems of our approach.
2. ARCHITECTURE OF MODUS
This section briefly describes the architecture of MODUS. More detailed description on the architecture is described in (Furuse, 1990).
The major goal of the research project on MODUS is to design and implement an extensible DBMS of practical use. For this purpose, it is aimed at minimizing the labor needed for introducing new basic data types and new access methods in MODUS. To achieve this, we have decomposed the functionality of DBMS and let each functionality be implemented by a manager. For coordinating behavior of managers, a kernel is provided in MODUS. Some managers can be extended by includ-ing modules defined by users. As managers are independent of each other, it is possible to put new modules under control of a certain manager without any influence on other managers. For example, as type manager is independent of access method manager, inclusion of new data types does not affect the behavior of access methods modules.
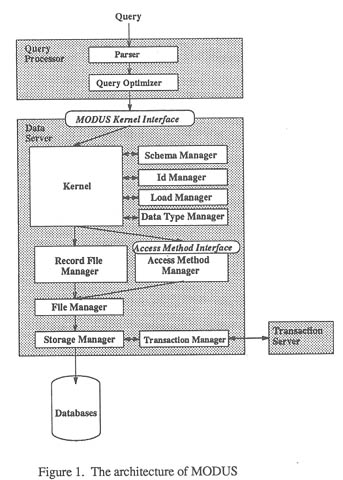
Figure 1 shows the architecture of MODUS. MODUS is composed of three process: data
server, transaction server and query processor. The main part of MODUS is the data server. The data server includes the kernel and some managers.
Data type manager in the data server manages all data types introduced into MODUS. Every data type is defined in a data type module. Users can introduce new basic data types into MODUS by writing data type modules. As system defined data types are also introduces by modules and any modules are handled in a uniform way, there is no difference between system defined data types and user defiance data types in MODUS. Using the data type modules, the data type manager constructs data type hierarchy. Users can modify the hierarchy by appending, deleting, and replacing data type modules (some important data type modules, such as those of Integer, Boolean and Bytes cannot be deleted).
Access method manager provides indexing mechanisms. In MODUS, each access method is defined in an access method module. The access method modules are controlled by the access method manager. Each access method module must contain a fixes set of functions called access method interface (AMI). AMI provides the kernel with fully abstract and uniform access functions. The kernel can access every index file by calling AMI functions without knowing which access method module is used to access the index file. Some access method modules which implement common indexing mechanisms including B-tree and hash file are provided in advance. Users can use these modules if they are well suited to the database applications. If they are not enough, users can modify the contents of modules or make new modules suited for their purpose from scratch.
When the kernel receives a query through MODUS kernel
interface, it consults the schema manager to find out whether the query
is valid. It also checks which files are needed to process the query and
which data types of objects are stored in the files by consulting the schema
manager. Next, the kernel gets record identifiers in the files fro the
access method manager through AMI. The records are received from the record
file manager by sending these record identifiers to the manager. Type information
is served by the data type manager. Using this information, the kernel
evaluates expressions included in the query. Results are sent back to the
query processor. More details are discussed in Subsection 3.4.
3. MECHANISM OF EXTENSION IN MODUS
3.1 Data Type Module
As mentioned in the previous section, in MODUS, each data types is defined in a data type module. The following are the contents of the data type modules:
Declaration of operations provided in the module
Definition of the data type
Definitions of operators related to the data type
Definitions of a pair of conversion functions
Definitions of other auxiliary functions used in the module
Each type of module must contain a pair of conversion functions called dump and undump. In MODUS, a data type named Bytes are provided for special purposes. Instances of the data type Bytes are used to store the data objects in the secondary storage. Users can specify structures of the data objects in the secondary storage by defining these conversion functions so that it is suited to the applications. The function dump converts the data objects of a certain data type (in main memory format) to those data type Bytes (in secondary storage format). Undump is the reverse function of dump.
3.2 Access Method Interface
As described in the previous section, the access method manager implements the indexing mechanism of MODUS. The role of the access method manager is to provide kernel with indexing service by controlling access method modules written by users. Here, the point is, from the kernel's point of view, that there must not be nay difference among access method modules to implement the extensibility. In other words, to be extensible, it is necessary for the kernel to control all access methods embedded into the system in a uniform way. To achieve this goal, we set an interface between the kernel and the access method manager. This is called access method interface (AMI) (Figure 2).
AMI is a fixed set of abstract functions. Table 1 shows the major part of AMI functions:
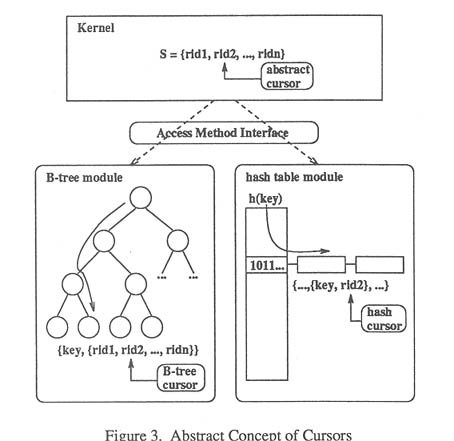
The specification of major functions of AMI is defined based on the concept of cursors (or iterates). A cursor is an abstract structure which moves on a set of record identifiers. Each cursor has its own context, and always points to one entry of the set on which the cursor moves. This entry is called current position. The concept of the cursors makes the indexing mechanism of MODUS comprehensive.
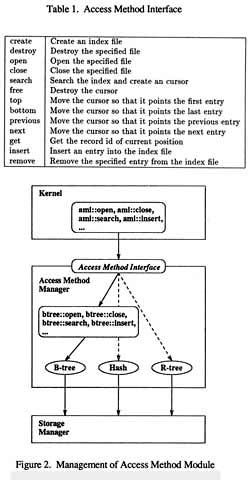
The concept of the cursors is a basis of abstraction of the indexing mechanism. Not only for searching entries in an index file, the cursors are also used to point out entries to be deleted or updated. As described above, to implement the indexing mechanism to be extensible, it is necessary to provide a uniform way to access index files. However, the implementation of an AMI function depends on the access method module. For example, consider cases of retrieving all record identifiers which are associated with a specified key value. In the case of a B-tree module, it follows the tree structure. On the other hand, in the case of a hash table module, it calculates the hash value followed by looking into the table entries (Figure 3). For making it invisible such difference among modules from the kernel, at AMI level, the abstract concept of cursors is useful. The implementation which depends on each access method such as tree traverse and table lookup is encapsulated into the cursors, and is hidden from the kernel. With the cursors, the kernel can access entries in index files in a uniform way.
In each access method module, users must give a concrete implementation of AMI functions as well as cursors. When the kernel sends requests using the cursor through AMI, then the access method module acts to answer the requests using its concrete definition of the cursor in the access method module.
3.3 Independence of Data Type Modules and Access Method Modules
As described in Section 1, for practical use, it is desirable that the data type extension and the access method extension should be orthogonal. This independence makes users' work to implement access method modules smaller. In MODUS, since every access method module has nothing to do with any data type modules, users do not have to write codes sensitive to each data type.
Furthermore, independence of data types and access method improves the reusability of user defined modules. For example, if an R-tree access method module is implemented independently of data types, this module can be used to index both two-dimensional and three-dimensional objects without any modification.
Figure 4 and Figure 5 are example of definitions of the examples of definitions of the R-tree access method and the data type Rectangle written in C++. In the access method module, AMI functions and cursor are defined. In the data type module, internal representation and some functions including the conversion function dump and undumb (see subsection 3.1) are defined.
Independence (and relationship) between access methods and data types are implemented by using an abstract data type Object. Object is the base data type for all objects stored in the databases of MODUS. Every data type in data type module must be subtype (or subclass) of Object. In access method modules, on the other hand, types of arguments of functions which apply the key values
must be of data type Object. In the R-tree access method module shown in the above example, the data types of the arguments of the function overlap are defined as Object. In the Rectangle data type module, the class Rectangle is defined for the objects of type Rectangle. Thus, in this case, we can construct the R-tree files which the data type of key values is Rectangle. This R-tree access method module can handle R-tree files of any kind of data types if that type has the function overlap. There is no need for modifying or recompiling this access methods module for every data type.
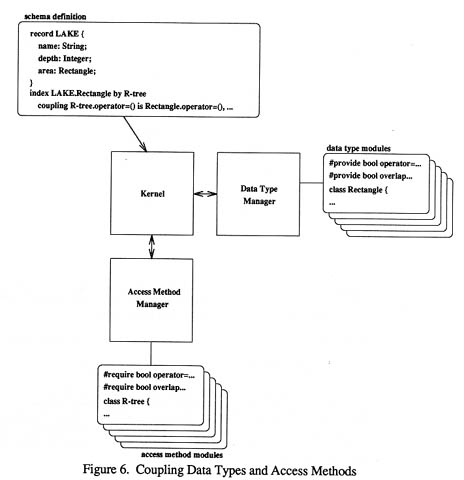
In each data type mode, it is possible to declare some algebraic characteristics (such as relativity, symmetricity, and transivity) of operators defined in the module by #provide director (note that the system does not check if the declared characteristics are really implemented in the definition of the operators. It is the users' task to ensure that the characteristics are implemented). On the other hand, in access method modules, the algebraic characteristics required for operators in the module can be declared by #require directive. Coupling of data types and access methods is determined in the schema definition for each database (Figure 6). In the schema definition, which operator in the data
type module is used in the access method module is described explicitly. When the schema definition is served to the kernel, it checks the validity of the coupling. If some of the provided operators do not satisfy the algebraic nature required in the access method module, the kernel refuses to make the database for the schema definition.
3.4 Query Processing in MODUS
With the examples of modules shown in the previous subsection, we can construct a simple application-specific DBMS that can handle two dimensional spatial data objects. In this subsection, we describe the mechanism of query processing with this spatial DBMS. Suppose that there is a database which includes following relations in our DBMS.
COUNTRY (name, population, area)
LAKE (name, depth, area)
We assume that data types of the attributes named area are both Rectangle. The attribute area of the relation LAKE is assumed to be indexed by the R-tree access method which is implemented by the access method module described in the previous subsection.
Consider that the following query is issued:
retrieve (LAKE.name)
where overlap (LAKE.area, COUNTRY.area) and COUNTRY.name= "Japan"

This query is to retrieve names of all lakes located in Japan. The function overlap is defined in the data type module of Rectangle shown in the previous subsection. This query is passed by the query processor and sent to the optimizer. The optimizer gets the schema information from the schema manager through the kernel interface and translates this passed query into query evaluation plans (QEPs). The query of our example will be translated to the following QEP:
R, I, and A are identifiers of relations, index files, and attributes, respectively. These identifiers are provided by the schema manager.
According to this QEP, the kernel decides its action by evaluating each expression in the QEP. First of all, the kernel consults the schema manager and checks whether the QEP is suited to the system catalogs of the database. then, the kernel calls functions in the access method modules through AMI to get record identifiers. In this example, the function search and the function get in the module R-tree are called. These functions then send requests to the file manager to read some pages of the index file in the secondary storage.
For each record identifier obtained from the index file, the kernel sends a request to the record file manager to get records in the database. At this stage, the function undump in the data type module Rectangle is used to convert sequence of bytes obtained from the storage manager to objects of type Rectangle. Other functions in tat data type module such as overlap are also used in the course of query processing. these functions are provided by the data type manager.
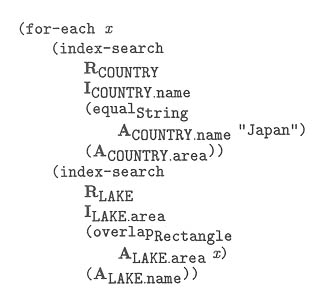
Results of evaluation of QEP (i.e., results of the query) are sent back to the query processor.
4. SUMMARY AND FUTURE WORK
In this paper, we described the mechanism for implementing the data type independence of access method modules in the extensible DBMS MODUS. This independence makes users' work to implement access method modules smaller. In MODUS, since every access method module has nothing to do with any data types, users do not have to write codes sensitive to each data type. Furthermore, when some new data types are introduced in future, users do not have to modify previously written access method modules.
Currently, part of MODUS has been implemented on SPARC station workstations running under SunOS 4.1. So far, prototypes of most managers, as well as the kernel, have been implemented. Also, some access method modules including B-tree, hash table, and R-tree have been implemented.
However, there are still some problems remaining. Design and implementation of some managers have not been completed. Design of the language for data type extension and implementation of the data type manager are currently some of the most important work still remain. In the example in this paper, although we use the C++ as an implementation language for user extension, this is not desirable. Instead, we are considering high level language for the sake of users' convenience.
Moreover, we have a lot of work in the future including an extensible query processor, rule based query optimizer generator, higher level concurrence control management, large object management, and full implementation.
REFERENCES
Batory, D.S. (June 1987). "Principles of database management system extensibility," IEEE Database Engineering, 6 (2).
Batory, D.S. (March 1988). "Concept for a database system compiler," Proceeding of 7th ACM SIGACT-SIGMOD-SIGART Symposium on Principles of Database Systems. Austin, TX.
Batory, D.S., J.R. Barnett, J.F. Garza, K.P. Smith, K. Tsukuda, B.C. Twichell & T.E. Wise. (November 1988). "GENESIS: an extensible database management system," IEEE Transaction on Software Engineering, 14 (11).
Batory, D.S., T.Y. Leung & T.E. Wise. (September 1988). "Implementation concepts for an extensible data model and data language," ACM Transaction on Database Systems, 13 (3).
Bayer, R. & E. McCreight. (1972). "Organization and maintenance of large ordered indexes," Acta Information, 1 (3).
Carey, M.J. & D.J. Dewitt. (September 1986). "The architecture of the EXODUS extensible DBMS," Proceedings of the International Workshop on Object-Oriented Database Systems, Asilomar, CA.
Carey, M.J.; D.J. Dewitt; J. E. Richardson & E.J. Shekita. (August 1986). "Object and file mana-gement in the EXODUS extensible database system," Proceedings of the 12th International Con-ference on Very large Data Bases, Kyoto, Japan.
Carey, M.J. & D.J. Dewitt. (June 1987). "An overview of the EXODUS project," IEEE Database Engineering, 6 (2).
Carey, M.J. & D.J. Dewitt. (June 1988). "A data model and query language for EXODUS," Pro-ceedings of SIGMOD International Conference on Management of Data. Chicago, IL.
Carey, M.J. & D.J. Dewitt. (February 1989). "Extensible database systems," Tutorial, the 5th International Conference on Data Engineering. IEEE .
Carey, M.J. & D.J. Dewitt. (December 1990). "Extensible database management systems," ACM SIGMOD Record, 19 (4).
Comer, D. (June 1979). "The ubiquitous B-Tree," ACN Computing Surveys, 11 (2).
Furuse, K. (1990 in Japanese). Design of the extensible DBMS MODUS. Master's thesis, University of Tsukuba.
Furuse, K.; Y. Ishikawa; K. Ymaguchi; H. Kitagawa & N. Ohbo. (December 1990) (in Japanese).
"Design and implementation technique of the extensible DNMS MODUS," Proceedings of Advanced Database System Symposium, Tokyo, Japan. IPSJ.
Graefe, G. and D.J. DeWitt. (May 1987). "The EXODUS optimizer generator," Proceedings of ACM SIGMOD 1987 Annual Conference, Francisco, CA.
Guttman, A. (June 1984). "R-trees: A dynamic index structure for spatial searching," Proceedings of Annual Meeting SIGMOD '84, Boston, MA.
Hass, L.M., J.C. Freytag, G.M. Lohman & H. Pirahesh. (June 1989). "Extensible query pro-cessing in starburst," Proceedings of the 1989 ACM SIGMOD International Conference on Management of Data. Portland, OR.
Hass, L.M., W. Chang, G.M. Lohman, J. McPherson, P.F. Wilms, G. Lapis, B. Lindsay, H. Pirahesh, M.J. Carey & E. Shekita. (March 1990). "Starburst mid-flight: as the dust clears," IEEE Transaction on Knowledge and Data Engineering, 2 (1).
Kim, W. and F.H. Lochovsky, eds. (1989). Object-Oriented Concepts, Databases, and Applica-tion, Addison-Wesley.
Lehman, T.J. and B.G. Lindsay. (August 1989). "The starburst long field manager," Proceedings of the 15th International Conference on Very Large Data Bases. Amsterdam, Netherlands.
Lohman, G.M., B. Lindsay, H. Pirahesh, & K.B. Schiefer. (October 1991). "Extensions to starburst: objects, types, functions, and rules," Communication of the ACM, 34 (10).
McPherson, J. & H. Pirahesh. (June 1987). "An overview of extensibility in starburst," IEEE Database Engineering, 10 (2).
Richardson, J.E. & M.J. Carey. (May 1987). "Programming constructs for database system imple-mentation in EXODUS," Proceedings of ACM SIGMOD 1987 Annual Conference. San Francisco, CA.
Rowe, L.A. & M.R. Stonebraker. (September 1987). "The POSTGRES data model," Proceedings of the 13th Annual International Conference on Very Largfe Data Bases. Brighton, England.
Samet, H. (1989). The Design and Analusis of Spatial Data Structures. Addison-Wesley.
Sellis, T., N. Roussopoulos & C. Faloutsos. (September 1987). "The R+-tree: a dynamic index for multi-dimensional objects," Proceedings of the 13th International Conference on Very Large Data Bases, Brighton, England.
Stonebraker, M.,& L.A. Rowe. (June 1986). "The design of POSTGRES," Proceedings of ACM SIGMOD '86 International Conference on Management of Data, Washington, DC.
Stonebraker, M., J. Anton, & E. Hanson. (September 1987). "Extending a database system with procedures," ACM Transaction on Database Systems, 12 (3).
Stonebraker,, M., J. Anton, & M. Hirohama. (June 1987). "Extendability in POSTGRES," IEEE Database Engineering, 10 (2).
Stonebraker, M., E. Hanson, & C. Hong. (February 1987). "The design of the POSTGRES Rules system," Proceedings of 3rd International Conference on Data Engineering. Los Angeles, CA: IEEE.
Stonebraker, M., A. Jhingran, J. Goh, & S. Potamianos. (May 1990). "On rules, procedures caching and views in data base systems," Proceedings of the 1990 ACM SIGMOD International Conference on Management of Data, Atlantic City, NJ.
Stonebraker, M. and G. Kermitz. (October 1991). "The POSTGRES next-generation database management system," Communications of the ACM, 34 (10).
Yu, X. (1990). Supporting Structured Objected in MODUS, PhD thesis, University of Tsukuba.
Yu, X., Y. Ishikawa, K. Yamaguchi, H. Kitagawa & N. Ohbo. (May 1991). "Object management in extensible database management system MODUS," Proceedings of the Symposium on Object-Oriented Software Technologies. IPSJ.