INFORMATION RETRIEVAL BY BROWSING
Kevin Cox
Department of Computer Science
City Polytechnic of Hong Kong
Kowloon, Hong Kong
E-Mail: CSCOXK@CPHKVX.BITNET
Abstract: This paper presents a model of information retrieval through browsing and compares it to information retrieval through query formulation. The advantages of browsing over query formulation are discussed and desirable properties of a browsing system described. It is suggested that a rich browsing system is sufficient for many information retrieval tasks and that query formulation and facilities are often unnecessary in information retrieval systems. Browsing as defined in this paper applies to most types of data such as text, photographs, drawings, equations and sound. The approach provides a common interface for most information retrieval tasks.
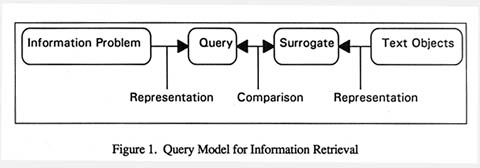
Information retrieval systems and research are dominated by the classic model represented in Figure 1 (Belkin and Croft, 1987). In this model there is a universe of objects to be searched, with
surrogates that represent the objects (such as indexing terms or keywords). A searcher with a query creates a description using the surrogate terms and the information retrieval system then matches the query against the surrogate representations and presents the matching objects to the user for their consideration. Users then examine the retrieved objects and select items of interest.
Even though this model has worked well and has adapted to changing technologies, many pro-blems still exist in its application ( Bates, 1989; Cooper, 1988; Willett & Wood, 1989). These can be summarized as:
User difficulties in query formulation
Null returns and too many matches
Variation in importance of query components and term dependencies
Adaptation to different forms of objects such as pictures and sounds
Finding good surrogate representations for objects.
Many have suggested that browsing, which uses the pattern recognition capabilities of human users, may help overcome some of these difficulties (Bates, 1989; Cove & Walsh, 1987; Marchio-nini, 1987; Hildreth, 1982; Oddy, 1977). However, even though browsing is seen as a way of overcoming many problems and as a way of making systems more usable it is normally seen as an adjunct to query based searching. The query model is still retained with browsing used to enhance queries through such mechanisms as relevance feedback and automatic query generation.
We have suggested elsewhere (Gorayska & Cox, 1992) that the formulation of computer repre-sentation of user models or queries is difficult to achieve with current technologies and that to be effective such systems require a much deeper understanding of human discourse and knowledge than is yet available. An adequate dialogue and formulation process may one day be possible, but not in the immediate future. We believe that systems based on explicit query formulation have limits imposed because of the mismatch between human and computer information processing.
This paper suggests that for many information retrieval tasks searching based solely on a brows-ing paradigm will work efficiently and effectively. Moreover, the proposed model and database structure are extendible to any database which can be viewed as a set of objects with definable identifying characteristics and on which measures of closeness can be calculated between objects.
This paper shows how to implement the Berry Picking method of Bates (1989). It is also an extension of the ideas of nearest neighbor searching as in Al-Hawamdeh et al (1991) and Croft & Walsh (1988). The TINLIB system also uses many of the same ideas with its browsing functions. (Noerr and Bivins-Noerr, 1985). While there are echoes of Hypertext in the model its operation is different as its searching procedures depend on object comparison rather than following interesting links.
This paper describes the browsing model by comparing it to the query model. A database structure to implement the model is presented. The designs of the database structure and browsing operations are driven by the functional requirements and user interface principles. For purposes of exposition the method is illustrated with an artificial problem domain. Finally a summary and extension of the ideas to other object domains are outlined.
2. THE BROWSING MODEL COMPARED TO THE QUERY MODEL
Browsing can be defined as an interactive search activity in which the direction of the search is determined by the user on the basis of immediate feedback from the system being browsed. Most users of most information retrieval systems exhibit browsing behavior no matter what the underlying system structure. For example, many readers are familiar with their own behavior when searching with query based systems in which results of their queries are used to create their next query. While browsing activity is an important part of searching in most systems in this proposal it is the only method of searching.
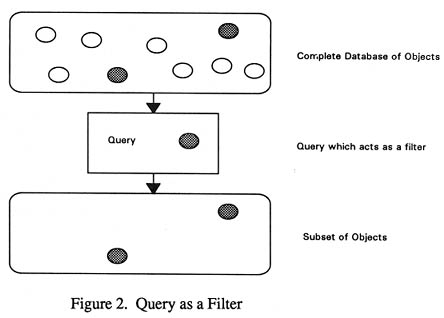
As well as viewing a query based system as in Figure 1 we can view it as defining a subset of objects that the user examines. Objects are selected from a loosely structured database using the values of object attributes (Figure 2).
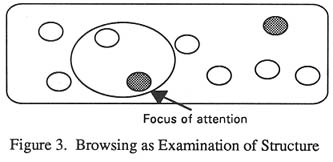
A search based on browsing requires the user to be positioned in a structured database. The user moves within this database on the basis of information receive (Figure 3). At no stage is a subset of items ever isolated from the database for separate consideration; rather the user moves through the whole database focussing on the areas of immediate interest.
The underlying model is different from a query based system even though the effect might appear similar. Query based browsing behavior uses the dynamic restructuring of the database based on the query formulation. In the browsing model the database remains the same, the user never explicitly formulates a query and only moves around the database.
3. MAKING BROWSING EFFECTIVE
The functional requirements for effective browsing systems are:
The ability for users to position themselves in an area of interest of the database
The ability for users to be able to recognize appropriate directions in which to further the search
The ability to easily move quickly and efficiently through the database.
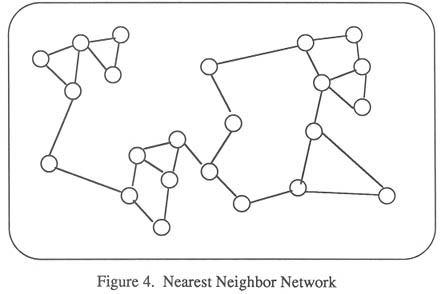
A key browsing requirement of a static database is for its structure to be understandable to the user and to have useful properties to help browsing. There are many ways to structure a database. Examples are a conceptual hierarchy or organizing by date of object entry. What is proposed here is to organize it on the basis of similarity with a nearest neighbors network (Figure 4). This approach has been suggested and used by others (Croft & Parenty (1985). It is used because it is a simple, general yet powerful organizing technique. The idea of similarity is understandable to users and any set of objects can be organized this way; providing we can measure closeness between objects. New structures are also easily created by using different similarity measures.
The approach has the advantage of allowing us to view the data spatially in two or three dimen-sions. There is the concept of direction that enables us to imagine a direction of similarity. Thus we can start with an object, see all the ones to which it is similar, and move in the direction which seems most profitable. The structure has a visual aspect that enables a user to navigate in appropriate directions. This ability to move in many directions contrasts with hierarchical systems in which the movement is often restricted to moving within the hierarchy.
One of the dominant themes in information retrieval research is that people use many different cues and clues to find information. People remember objects by associating them many other objects and events. A browsing system on a static database structure requires a rich vocabulary of interac-tion and associations. The nearest neighbors model accomplishes this by creating nearest neighbors networks for all the different objects within the database and by creating different similarity net-works. All interesting databases have different types of object. For example a database of video tapes will have actor objects, producer objects and year of production objects. Any characteristic that describes an object can itself be an object. All characteristic objects can have nearest neighbor networks constructed. As well each set of objects can have nearest neighbor networks constructed or derived between object sets. Figure 5 shows a simple set of networks.
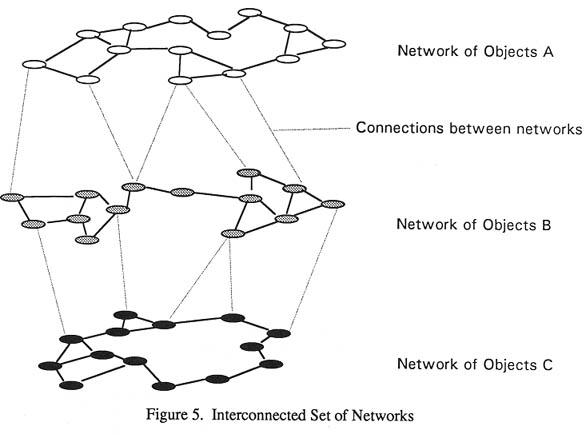
This rich set of interconnected networks provides the structure for browsing. The design of an appropriate set of networks and the design of similarity measures is an area for much investigation, but the simplicity and versatility of the structure allows good browsing structures for most domains.
One reason for the relative neglect of pre-coordinate information retrieval systems is the belief that too many objects have to be examined during retrieval. If there are few networks with little interconnection then this is true. The network described does not suffer from this problem as work-ing between different networks of objects enables a quick focussing of areas of interest and acts in a similar manner to the focussing of interest via query modification.
The nearest neighbor networks enable the implementation of simple directional strategies. For example, if a user decides that the area of interest is similar to two objects then the focus of attention can be directed to objects on a short path between the two objects (Figure 6). This idea extends to many items both within and between networks so allowing a simple mechanism for navigation.
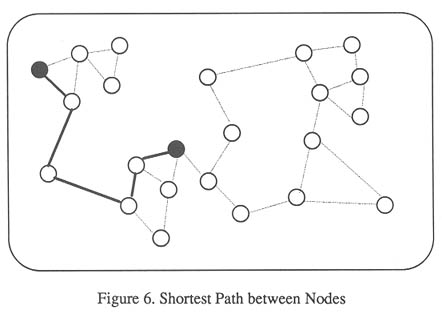
A browsing environment can be made as complex and as rich as needed
for a particular problem domain. The simple nearest neighbor model of layers
of separate objects with connections between the layers provides an extendible,
consistent mechanism for achieving such an environment. It is not necessary
to make connections between each pair of nearest neighbor networks. Only
one is required as other connections can be estimated.
4. USER INTERFACE DESIGN FOR INFORMATION RETRIEVAL
There are many well known design principles we can follow to assist us to design an interactive system (Cox & Walker 1992). Important ones for an information retrieval application are:
People choose items rather than generate input.
Use the recognition and discrimination capabilities of people.
Make things visible.
Use the spatial capabilities of humans.
Make interactions rapid.
Make the interface reflect the underlying model of how the system works and make this apparent to the user.
Leave the user in control of the interactions and make it easy for them to create useful concep- tual models of the system operation.
The system design presented here was driven by these user interface considerations. Design driven by user interface principles is likely to result in a different system from that driven by retrieval algorithms (Cox 1992). The choice of a set of layered networks of objects was made because it both fitted the logical requirements of the problem, but more importantly it is a structure that allows us to easily apply the interface principles. The next section describes a small artificial application showing the use of the principles.
5. A SIMPLE INFORMATION RETRIEVAL PROBLEM
In the following example application the database consists of drawings of the type shown in Figure 7.
In this drawing there are an arbitrary number of ellipses, squares, circles and squares of different shapes, shadings, sizes and positions. These are stored in a database and the user wishes to find diagrams that they may use for some purpose. These purposes are often unknown to the designer of the application.
This problem is typical of most information retrieval systems. There is a set of objects (in this case the drawings) with different characteristics (the shapes can themselves be considered as objects) combined together in various ways. A user has a purpose for investigating the database. The infor-mation retrieval problem is to find those objects that best fit the user's needs. In a traditional system the user would formulate a query to express their needs by either drawing a representation of the item to be found or by specifying it in some manner with some other language, such as:
Shaded Circle at middle right, square in top left, etc.
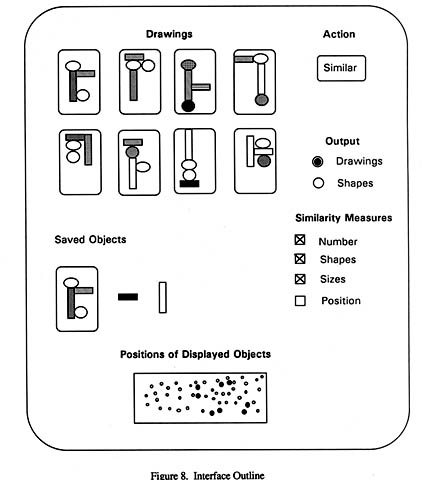
In the system discussed here the user searches by browsing and recognizing. When an item of interest is found then it is saved. Figure 8 illustrates a possible dialogue for searching. The opera-tions to support that dialogue are described below.
The operations available to the user are:
Select a drawing or a shape. Clicking on a shape selects that shape. Clicking on a blank part of a drawing selects the drawing.
Double clicking on an object puts it into the saved area. Items in this area can be used for later selection as we browse around through shapes or diagrams. (The shape could also be dragged to the save area.) Double clicking on an item in the save area removes it.
Shapes and/or drawings are selected then the operation similar is applied. This gives another set of drawings or shapes similar to the shapes and drawings selected.
Information retrieval is thus achieved by the primitive operations of:
1. Selecting objects or characteristics.
2. Finding a set of similar objects to those selected.
3. When an interesting object is seen then it is saved.
This is the general model for any information retrieval system using this approach. The key factor is the definition of what similar means. In the example similar finds other drawings that have similar shapes to those selected.
The area titled Positions of Displayed Objects gives a two dimensional
picture of the space for the drawings and shows where in the nearest neighbor
space the displayed objects are positioned. The two dimensional representation
of a nearest neighbors network is a non trivial problem and is the subject
of further investigation.
6. DISCUSSION OF THE SYSTEM
Is this system different from other information retrieval systems?
Many other systems have similar features because all information retrieval systems have some form of browsing. The saved area is the result of selection by the user and contains items that the user thinks might be interesting. The saved items may or may not be used in later similarity opera-tions and searching is achieved by the user recognizing items of interest. The only searching opera-tion in the system available to the user is to ask the system to show items close to others. The effect
of the user doing many of these simple operations may be the same as a user creating a sophisticated query, but the browsing strategy, as discussed here, never requires the system to evaluate or com-pare, only display its internal structure.
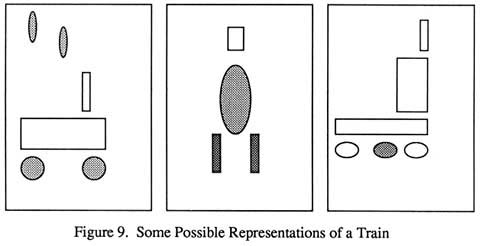
To illustrate this consider the diagrams in Figure 9 that may be retrieved by a user. Here the user wanted to find a representation of a train. Most information retrieval systems would require the user to formulate a query in ways that described a train. Unfortunately the user may have little idea of how to do this without seeing the diagrams in the database. Some systems attempt to try to under-stand the user request by building a "user model" as expressed by the user. Clearly both these approaches have severe limitations and problems of usability. The approach suggested here is a more general approach as it leaves the problem of meaning and relevance in the mind of the user. Some of the techniques in many information retrieval systems can be borrowed to help the user browse, but the focus of control and the decision on what constitutes a search hit is left with the user.
7. HOW THIS BROWSING SYSTEM ADDRESSES IMPORTANT INFORMATION RETRIEVAL CONCERNS
The browsing system as described will satisfy important usability criteria. It will be fast because it is a pre-coordinate system, it is simple as there is only one basic operation, it is adaptable as it applies to any set of objects, it is versatile as different similarity conditions can be created, the user is in control and never needs to explicitly formulate a query and it gives a rich environment for creative browsing.
The system builds upon much known research and many other information retrieval systems. The contribution here is to remove the need for query formulation, to simplify the underlying struc-ture in a form that matches interface design requirements and to present a simple interface within which to incorporate other techniques and strategies.
This paper has not discussed other features such as the emergent properties
of nearest neighbors networks, the adaptation of the network as people
use the system, the use of the system to answer queries, the use of the
system as a classification tool or the application of the method to different
types of objects such as text, photographs, equations and sounds. These
are the subject of ongoing research.
REFERENCES
Al-Hawamdeh, S., de Ver, R., Smith, G., & Willett, P. (1991). "Using nearest-neighbor search-ing techniques to access full-text documents," Online Review, 15 (3/4): 173-191.
Bates M.J. (1989). "The design of browsing and berrypicking techniques for the online search interface," Online Review, 13 (5): 407-424.
Belkin, N.J. & Crof, W.B. (1987). "Retrieval techniques," In Annual Review of Information Science and Technology (ARIST), 22: 109-189.
Croft, W.B. & Walsh, B.C. (1988). "Online text retrieval via browsing," Information Processing and Management, 24: 31-37.
Croft, W.B. & Parenty, T.J. (1985. "A comparison of a network structure and a database system used for document retrieva," Information Systems, 10 (4): 377-390.
Cooper, W.S. (1988). "Getting beyond Boole," Information Processing and Managemen, 24 (3): 243-248.
Cove, J.F. & Walsh, B.C. (1988). "Online text retrieval via browsing," Information Processing and Management, 24 (1): 31-37.
Cox, K.R. (1992. "User driven design versus algorithmic driven design for systems develop-ment," Working Papers of Department of Computer Science the City Polytechnic of Hong Kong. pp.2-11.
Cox, K.R. & Walker, D.W. (1992). User-Interface Design. Englewood, NJ: Prentice-Hall.
Gorayska, B. & Cox, K.R. (in print). "Expert systems as extensions of the human-mind in artifi-cial intelligence and society."
Hildreth, C.R. (1982). "Online browsing support capabilities," In Proceedings of the ASIS Annual Meeting, 19: 127-132.
Marchionini, G. (1987). "An invitation to browse: Designing full-text systems for novice users," The Canadian Journal of Information Science, 12 (3): 69-79.
Noerr, P.L. & Bivins-Noerr, K.T. (1985). "Browse and navigate: An advance in database access methods," Information Processing & Management, 21 (3): 205-213.
Oddy, R.N. (1977). "Information retrieval through man-machine dialogue," Journal of Documen-tation, 33 (1): 1-14.
Willett P. & Wood, F.E. (1989). "The use of the instruct text retrieval
program at the Department of Information Studies University of Sheffiel,"
Education for Information, 7: 133-141.