Yu Zeng & John N. Crossley
Department of Computer Science
Monash University
Australia
E-mail: ZENG@BRUCE.CS.MONASH.EDU.AU,
JNC@BRUCE.CS.MONASH.EDU.AU
Abstract: This paper describes the design and implementation of an X Windows1 (foot note here) based Chinese Word Effective Retrieval (CWORDER) system. The CWORDER is able to allow users dynamically and rapidly to store or retrieve Chinese word information such as pronunciation (Pin-Yin), speech mode, English equivalents, usage explanation and other relevant information to or from standardly organized or user-defined information-base files. It is particularly aimed at non-Chinese speakers, or people wanting to learn Chinese, or even simply to recognize certain Chinese characters and words. Such a system would also be useful as a tool to assist Chinese word and attribute studies, as well as Chinese electronic directories and information systems.
In the paper, the system design principles, information file organization, index structures, retrieval mechanism, and user interface design will be discussed.
The major difference between Chinese and Latin languages such as English, French, etc. is that written Chinese uses ideographic characters, namely Hanzi. Each character is represented by a unique two dimensional structure. The Chinese language contains over fifty thousand such charac-ters, most of them not longer used (Liu, 1984). GB2312-80, the Code of the Chinese Graphic Character Set for Information Interchange, defines 6763 Hanzi used in modern Chinese society.
The initial motivation for this project came from the idea of developing a comprehensive elec-tronic Chinese-English dictionary which could assist non-native speakers to learn Chinese or even simply to recognize certain Chinese characters. That is, given certain input resources, the system should allow the user to get back from the dictionary information helpful to the user for under-standing and retaining the related Chinese words. Such information should at least include the pronunciation of the retrieved Chinese word, its speech functions, and its English equivalents, etc... These attributes are generally essential for all word entries, and are easily formatted. During the course of the system design, we realized that some other information, such as bilingual examples of usage, idiomatic phrases using the word, or even pictorial explanations, would definitely benefit learners further, and moreover, the less formatted nature of these data posed challenges for us to design a more general, more widely useful retrieval system while examining more sophisticated techniques for data storage and retrieval. Other than merely a conventional dictionary, our aim is to build an integrated Chinese word information retrieval system under a graphic window environment.
2. DESIGN PRINCIPLES
From the point of view of machine translation and natural language understanding, an electronic dictionary should be designed to contain as many entries as possible with the maximum possible linguistic information attached to each entry. This is because the quality of the dictionary will greatly influence the quality of the output produced (Ye, 1988). However, in the case of designing a retrie-val system to assist individuals to learn languages, the situation is quite different in some senses: On the one hand, the more linguistic information each entry contains, the more the dictionary helps the learner; on the other hand, however, a relatively complete dictionary system, say including at least 20,000 word entries, might not help the learner much because:
Beginners usually have a very limited vocabulary, and are not expected to increase this very much over a short period. Therefore, most of the infrequently used words in a relatively large dictionary are not accessed at all, and much data is redundant in this case.
Advanced students already have a reasonably large vocabulary, and therefore, very frequently used words are probably unnecessary for them.
A large dictionary reduces the system performance in terms of access time and space.
One solution is to allow users to create their own personal dictionaries which can be dynamically updated so the user-dictionaries always keep the users' most useful information. On the other hand, the construction of a general Chinese word information base is necessary so the user can capture word information from it.
Another requirement is that the word entry and annexed information should be linguistically rich to not only help people learning Chinese but also possess value for Chinese language studies.
We believe the following features are essential in designing a prototype retrieval system:
Flexible and rapid retrieval methods,
Efficient information organization,
User-friendly interface.
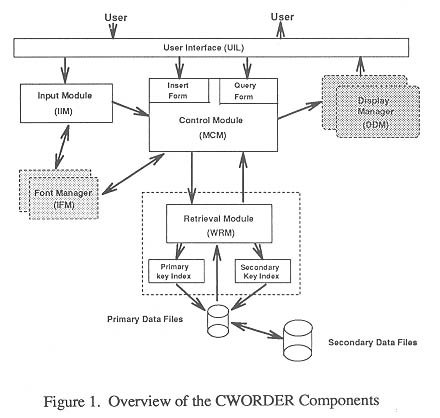
An overview of the CWORDER components is shown in Figure 1.
Ideograph Input Module (IIM) facilitates a user to input Chinese characters by their attributes such as GB code, Pinyin, stroke counts, radical etc. Selected characters then are sent to the Main Control Module (MCM) for further processing such as forming a query sequence. The MCM also provides users-filling-form style interface for dynamic update functions. Word Retrieval Module (WRM) carries out various retrieval operations on the information base files, and the results are sent to the Result Display Manager (RDM) for presentations on the window-based screen.
3. LOOKING-UP PROCEDURE FROM A PRINTED DICTIONARY
As mentioned before, our project is to store and retrieve information at the Chinese word level. Each Chinese word entry may be annexed with many attributes and much information. How can we computerize this information properly? Before we delve into the details let us first analyze human looking up procedure from a printed dictionary.
The following sample entry is taken from a Chinese-English dictionary published by the Beijing Foreign Language Institute (1988), which is widely used in Mainland China.

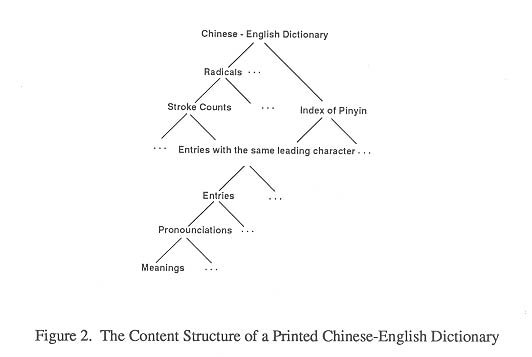
When some one looks up such a Chinese word, the first thing coming to mind may be the radical and stroke count of the leading character of the word, or, alternatively, the Pinyin symbol for the character. After checking the Radical/ Stroke Index Table or Index of Syllables of Pinyin, a set of characters with the same radical and stroke count or Pinyin pronunciation will be found, and then from this set he chooses the leading character of the word he is looking for. A set of entries in which each has the same leading character can then be found by means of the character. Finally, from this set, the user finds the word entry and associated entries with annexed information that he wants to know or learn.
Such a retrieval procedure can be represented by the layered structures shown in Figure 2.
In another alternative, the dictionary can be defined in more details using BNF:
Obviously, the definition reflects the one-to-many relation between a Chinese word and its English equivalents. Associated words for a given Chinese character or word are also defined. Such a dictionary is comprehensive but cannot be used directly in an electronic format. Our goal is to find appropriate ways to define the dictionary and simulate the retrieval procedure inside a computer, furthermore, other than a conventional dictionary, we want the system having the certain
capability of automatic indexing and retrieving the concerned word records by free English terms.
We can summarize by saying that such a Chinese-English dictionary has the following charac-teristics:
Each ideographic character or word can uniquely identify the corresponding entry.
The Pinyin attribute cannot distinguish words uniquely.
Each Chinese word has multiple meanings.
Almost all single-character entries are accompanied with associated words which share the same leading character.
There is annexed free textual information.

We can divide the information for each entry into two levels of importance. The word itself, Pinyin (pronunciation), the speech mode or parts of speech and English equivalents will be regarded as primary information because they are usually the most basic attributes for a Chinese word entry, and they are formatted relatively easily. Supplementary information refers to idiomatic usages, bilingual examples, or information annexed to the entry item. This level of information may be free text and can even be expanded to include other information (e.g. pictorial information) in the future.
This information classification has the advantage
of convenience and efficiency in organizing the information into a computer.
The primary information is relatively precise and formalized so we can
easily and quickly process it. In contrast, the supplementary information
is not formalized and may be free texts. The over-riding policy is: this
level of information will be presented only if the user needs it.
The above sample entry can be refined and formatted as follows for processing in an electronic format:

Here ``%'' indicates an entry record, ``< >'' a speech mode, ``:'' is a data field separator and ``{ }'' indicates supplementary information (linked through a pointer).
In the following sections, we discuss information storage and retrieval methods based on the above information classification.
4. INDEXING STRUCTURES AND RETRIEVAL
The CWORDER provides two types of index structures for searching: one is for searching Chinese words, their attributes and annexed information in a conventional way by means of the content structure of a Chinese-English dictionary discussed earlier. To meet the requirement, we proposed and implemented a so called HDTR index structure for this conventional search function which is based on a combination of a partial hashing function and a dynamic tree structure.
The HDTR structure can be illustrated as in Figure 3. Each node is a Chinese character repre-sented as its Pinyin in the figure.
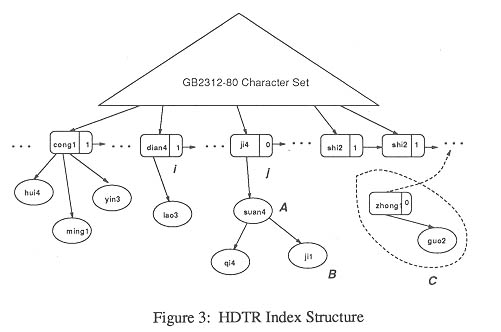
The HDTR structure has demonstrated the following advantages:
Rapidly retrieval: for Chinese words with only one character, the search time is ideal O(1), and the comparative complexity is only related to the size of search key but not the size of the whole data collection.
The index structure responds to the dynamic growth of the data size very well.
There is good space utilization compared with conventional indexing methods such as B-Tree, inverted file etc... (Faloutsos, 1985; ,Lesk, 1988).
Unlike the hashing method, the HDTR structure preserves the natural order of associated words.
Under such an index structure, the wild-card functions(inexact matching such as *, ?) are also supported.
The second type of indexing structure is based on the Signature File method (Salton, 1983). The user can use other attributes such as Pinyin, English equivalents, etc... to form a search expression, or Boolean expression, in conducting retrieval of relevant word information records. The idea behind this is that usually no such attribute can uniquely identify a Chinese word record. Another reason we choose signature file approach is that it can support dynamic growth of data easily, and also has a reasonable retrieval speed when applied to a medium size data base.
When adding new word records or updating the information bases, the CWORDER also provides certain automatic indexing functionary by scanning the attribute part of a Chinese word record, and selecting those key words as descriptors of the records by rejecting those less meaning-ful words such as "in", "the", "and" etc... from a stop-list file. Therefore users can also retrieve related records via complete English phrases (e.g. "the meaning of a word" will be analyzed and only "meaning" and "word" are superimposed as query keywords).
5. FILE ORGANIZATION
Two types of data files are defined as shown in Figure
4.
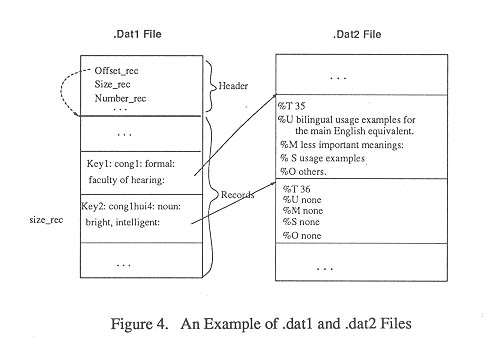
The Header and Records parts constitute the .dat1 file while lines of free text information form the .dat2 file. The .dat1 file is structurally organized and unreadable by humans but .dat2 file is human-readable and there is a blank line between reference items. All references in the file are assigned a tag, which in company with the file name, forms an address to be linked by the pointer to corresponding records in the .dat1 file.
One reference item in .dat2 files may typically contain the following lines of information:

In the .dat1 file, the idea of using the header structure is, of course, to speed up the access to the .dat1 file. The Header contains all necessary information from the whole file such as: the offset to Records part, the size of each record, the number of records, etc... Once the file has been opened, this part will be loaded into the main memory. The following records are arranged sequentially: they have fixed size and fields. The tag for the $i$th record is also stored as a pointer value in corresponding node to the HDTR index structure.
The search of the data file is very straightforward: by the address stored in the HDTR index, say it is i, we need not examine the Index-bit sequence pattern at all, using offset_rec + i * size_rec to get the start address in .dat1 file and retrieving the desired contents. Similarly the corresponding textual reference in the .dat2 file can be retrieved by the tag number in the address field.
6. USER INTERFACE
The X window system was initially developed at MIT to meet the needs of Project Athena (Scheifler, 1986). It provides a high-performance, high-level, network-transparent and device-independent graphical user interface. It is built on the client-server model, so it makes X applications extremely portable and allows a network of heterogeneous machines to share displays and input devices. Through the X Window System, users can access applications on machines other than their own workstation. One of the important features is that X provides primitives to support several policies and styles rather than mandate a particular user interface as in most window systems (e.g. Macintosh).
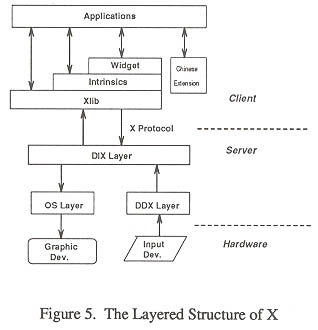
The X Window System is a network window system with three essential components: clients, server, and the X window protocol (Figure 5.) shows the layered structure of X and the client-server relationship.
An X client is an application that uses the X Window System to interact with the user. An X server provides window services to clients such as managing windows within which the client can draw and write text. At the lowest level of the X application environment are the X protocols which communicate between servers and clients. On top of X protocols is the Xlib. To create an X interface using the Xlib function calls is a difficult and time consuming task. The introduction of X Intrinsics and widgets has eased development.
The efforts to build a user interface for the CWORDER system include two aspects:
1). The extension of the X Window System. ``Extension'' here means having it provide the input/output capability for the Chinese characters without affecting the original functions for ASCII string handling. Our approach for the Chinese extension to X starts from the Xlib layer, the basic steps include defining internal code representations for Chinese, adding Chinese input functions and generating Chinese display fonts in X format. The remaining issues are how to handle Chinese correctly in the various software layers of X, such as relevant routines in Xlib and high-level Intrinsics and widgets. Many widget sets and the toolkit (e.g. Athena Widgets, HP X widgets, Motif Widgets etc.) are built on the top of X Intrinsics. We chose Athena X Widgets as our experimental platform because it is the most mature and popular one. Another matter necessary for Chinese extension is to build new Chinese-related widgets using the data structures defined by X Intrinsics (Young, 1989). The advantages of creating appropriate new widgets are that they are reusable and efficient. In fact, the independent Chinese ideograph input mechanism is such an attempt to create a new widget.
2). Building the user interface. The final interface view is as in Figure 6 and contains the following components:
An Independent Ideograph Input Mechanism:
This window is created as a new widget class. In fact, there are two ways
to implement the input module: one is to directly incorporate the codes
into the system main module; the other way is to create an independent
input mechanism which can generate Chinese characters for the whole system
but not bound to some particular window. The input module will not be involved
until some windows need to input Chinese. We adopt the latter scheme to
make the system more function-independent and efficient. The input window
currently supports four input methods: Guobiao, Pinyin, Wubi and Common
Character Input which is a
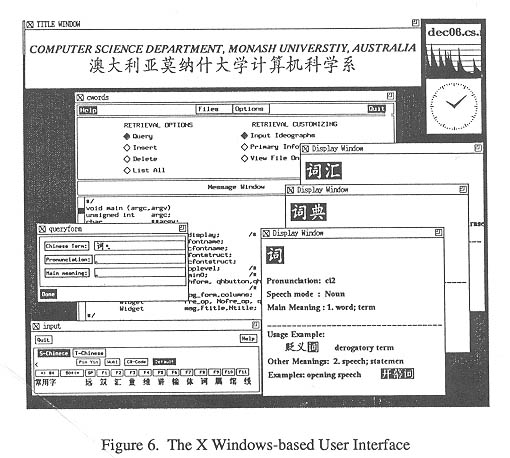
typical whole character input method, and permits the user to select desired characters from a pre-defined common character set which contains the 588 most frequently used Chinese characters (they are arranged in the order of decreasing in frequency).
Insert-Form and Query-Form Windows: These are windows used to facilitate data storage and queries in the system. Providing appropriate data insert and query methods in such a dynamic retrieval environment is important. Obviously, form-based insert and query methods are easier to learn and use than command-line-based methods. Basically, each form consists of a set of fields -- one for each Chinese attribute - and each field is editable. The insert-form contains the following fields: Chinese word, Pinyin, speech mode, main English equivalent and free-text based usage information fields. For the query-form, the speech and usage fields are not necessarily included because they are not used as querying attributes. Obviously, one advantage of a form-based query method is allowing simple combinations of criteria in different fields.
Display Windows: The retrieved result is presented within a two-part display window. The upper half of the window is filled with the primary information while the lower half window has the supplementary information, if any. If more than one record is retrieved, the corresponding number of display windows will be opened. The window-based information presentation inherits the characteristics of X Windows: each window looks like a Hypercard in Macintosh, and can be re-sized, moved, iconified, or closed.
Main Control Window: The main control window
provides file and retrieval function controls: e.g. files setup, function
selecting, system configuration etc... One other important role of this
module is to coordinate activities among various modules. The pull-down
menus, files and options are used to setup, open or write back the user-defined
data files. A set of toggle buttons on the main control panel has been
created for users to select the desired retrieval options. The message
window reports to the user the various messages such as retrieval successes
or failures, error messages etc... Below the message window is the keyword
view window which lists and highlights the related keyword set modified
by query formula.
7. CONCLUSION
This paper approached the design and implementation of a Chinese word domain information retrieval system while attempting to demonstrate the following strengths:
Rapid and dynamic retrieval methods;
Efficient information organization;
User-friendly interface design.
The implemented prototype contained more than 1000 randomly selected sample entries from (Beijing Institute of Foreign Languages, 1988), and has demonstrated that the idea and techniques used are successful. Indeed the practical usability and efficiency can next be evaluated in a real world situation based on a larger word information collection.
The system can be used as a comprehensive Bilingual (Chinese and English ) electronic dictionary system or further developed as Chinese textual information retrieval systems (Library, Biography systems etc.), moreover, non-textual information such as pictures, sound, etc. can be incorporated into the framework to make it have multimedia information processing capability.
REFERENCES
Beijing Foreign Language Institute. (1988). A Chinese - English Dictionary. Beijing: Business Publication House.
Faloutsos, C. (1985). "Access Methods for Text," Computing Surveys, 17 (1).
Hartson, H.R. & HIX D. (1989). "Human-Computer Interface Development Concepts and Systems for Its Management," ACM Computing Surveys, 21 (1).
Lesk, M.E. (1988). "Inverted Indexes with Low Storage Overhead," Computing Systems, 1 (3).
Liu, Y.Q. (1984). Language Use and Modernization - The Study of Chinese Information Processing, New Papers on Chinese Language Use. Australia: Australia National University.
Myers, B.A. (January, 1989). "User-Interface Tools: Introduction and Survey," IEEE Software.
Scheifler, R.W. & Gettys, J. (April, 1986). "The X Window System," ACM Transactions on Graphics, 5 (2).
Salton, G. & McGill, M.J. (1983). Introduction to Modern Information Retrieval. McGraw-Hill Book Company.
Somogy, Z. (1990). The Melbourne University Bibliography System. TR 90/3, Melbourne, Australia: Dept. of Computer Science, The University.
Tseng, S.S. et. al. (August, 1988). "Approaches on an Experimental Chinese Electronic Dictionary," In Proceedings of ICCPCOL'88, Toronto, Canada.
Ye, L.X. (1988). "Network Implementation for a Natural Language Translation Dictionary," In Proceedings of ICCPCOL'88, Toronto, Canada.
Young, D.A. (1989). X Window Systems Programming and Application with Xt. Englewood, NJ: Prentice-Hall, Inc..