
Figure 3. A Reply to Robertson or Robinson?
William Paisley
Knowledge Access Inc.
Mountain View, CA 94043, USA
E-mail: bill.paisley@forsythe.stanford.edu
Abstractt: This paper discusses how full-tex databases are developed for electronic publishing.
Full-text collections are the fastest growing part of the electronic literature. These collections consist of books, journal articles, reports, and databases in various combinations. They are widely available on CD-ROM, commercial online database services, and the Internet.
Knowledge Access Inc. has produced full-text CD-ROMs since 1985. We also facilitate the production of full-text CD-ROMs by publishers, government agencies, libraries, and corporations that use our KAware software for authoring, premastering, and recording discs. This paper will discuss the challenges of full-text retrieval from the perspective of CD-ROM. Its frame of reference is a full-text CD-ROM collection of books, reports, and/or journal issues that all pertain to the same general topic such as acid rain research, health promotion, tropical agronomy, government regula-tions, computer maintenance, etc.
To search for information on a full-text CD-ROM, the searcher typically relies on an index generated from all substantive words in the text. Phrase searching, wildcard searching, proximity searching, and Boolean AND-OR-NOT operations are usually available. Relevance ranking of "hits" is available in some search programs. Hypertext links between related sections of text are not usually present. However, some search programs allow the searcher to highlight any word or phrase in the text display and jump to other occurrences. This feature is called intrinsic hypertext because it utilizes words in the text file and does not depend on inserted links (extrinsic hypertext).
Reliance on the word index makes full-text searching difficult. Errors in the source docu-ments, technical vs. popular vocabularies, careless writing, and linguistic ambiguities cause the searcher to miss relevant sections.
Once a relevant section is found, jumping to other relevant sections is a desirable feature that cannot be implemented via hypertext links in most full-text CD-ROM collections because of the editorial cost of inserting origin links and destination links in as many as 200,000 pages per disc.
The next major step beyond hypertext may be called homologous retrieval or "retrieving more of the same". That is, the text itself is the origin of the search. The searcher's request is, "Show me other sections that are similar to this section, in rank order according to similarity." The search program assesses the content of the originating section, finds other sections with similar con-tent, and presents them in rank order. The similarity algorithm utilizes information that is obtained directly from the text file.
Approach. With support from the National Library of Medicine (NLM grant 1-R43-LM05460-01), we have been conducting research on algorithms to enable homologous retrieval in full-text databases without the need for editorial markup such as hypertext linkage. These algorithms analyze and transform information from a text file during regular processing of the file in preparation for CD-ROM production.
Our approach is based on the conversion of salient information from each section into signa-ture files. Signature files are a form of text representation in which information from each section is compressed in a much smaller coded file that can be searched quickly to determine if the section may be relevant to a query. Unlike an inverted index, in which the words from a section are dis-persed in their alphabetical locations, a signature maintains all of its information about a section in one unit of storage. It is a direct surrogate of its section.
In this project, a signature is a string of about 1,000 bytes in which the frequency or simply the presence of content attributes are marked for each section. Proper nouns and distinctive phrases can be marked by their presence only. Common nouns, verbs, and qualifiers are more indicative in a signature if we know their frequency of occurrence.
Signature files were initially proposed as a fast means of screening text against a searcher's query. Words in the query are mapped into a query signature, which can be compared with the text signatures for degree of similarity. In small databases found on hard disks, this is a promising application of signature files.
While we are interested in practical searching based on the relationship of a query signature to text signatures, our present focus is the relationship of text signatures to text signatures, which can be computed during the text processing phase. A full CD-ROM may contain 50,000 sections of 10,000 bytes each (roughly four pages). Typical CD-ROM workstations are not fast enough to compute coefficients of similarity between a query signature and 50,000 text signatures in real time even with algorithms that first examine "signatures of signatures" to determine which text signatures are worth the time required to compute their similarity with the query signature.
Signature file searching is probabilistic. It is possible that two sections with similar signatures are unrelated to each other from a searcher's perspective in which some words are important but others are not. We are in the process of designing a highlighting feature by which a searcher can accord more weight to certain words in the signature comparison.
Procedure. MEDLINE records were utilized in order to have MeSH (Medical Subject Heading) descriptors available for building and testing the signature files. Titles and author abstracts provided original full text. MeSH descriptors provided independent classification of the topics covered in the full text. More than 36,000 MEDLINE records were drawn from the topic areas of health promotion, patient care, cancer treatment, medical science, and health care policy and planning.
With the goal of building a test signature of roughly 1,000 markers that could distinguish among articles on different topics, we gave first consideration to words that are already found in MeSH descriptors. They comprise a carefully constructed medical vocabulary with wide coverage. However, the number of MeSH descriptor words far exceeds the desired number of markers in the signature file. For example, there are 13,696 different MeSH descriptor words just in the 9,166 medical science records that were downloaded for this project.
An effort to reduce the size of this vocabulary through cluster analysis was unsuccessful. Clusters that are based on word co-occurrences in MeSH tend to focus on phrases that reflect only the structure of MeSH itself (e.g., "Adjuvants, Immunologic - Therapeutic Use"). The resulting words are not representative of the full-text sections.
We therefore derived signature file markers from the database of full-text words, which were aggregated, sorted, deduplicated, and grouped into families of wordstems using our own stemming dictionary (for example, "analy" represents "analyze", "analysis", "analyst", and five other common forms). In three iterations involving the assignment of leftover words, this procedure yielded 1265 markers.
Results. The 1265-word signatures were tested for their ability to identify related topics and reject unrelated topics. The discrimination power of the signatures was evident if not yet adequate. In 13 out of 15 trials, the first section retrieved on the basis of signature similarity was a correct retrieval. However, variance analysis showed that many of the markers have no discrimination value in this set of topics. Some words lose their discrimination power because their frequencies are highly influenced by field of occurrence. For example, "abilit(y)" has a normalized mean of 93 occurrences in abstracts, 18 in titles, and only 1 in the descriptor field.
It became clear that the five topics used in this project are only a small fraction of the content areas that will have to be analyzed in order to understand patterns of usage and to develop a robust signature for health care literature.
Directions for further development. Homologous retrieval is an intuitive mode of finding information. The capability of "retrieving more of the same" has been successful in small databases with hypertext links. However, editorial markup is not the solution for full-text CD-ROMs totaling 200,000 pages.
We believe that signature files can serve the purpose of automating markup for homologous retrieval. They can be computed when text files are being prepared for CD-ROM production, at the same time as conventional indexing. Existing search programs can be modified to support homolo-gous retrieval.
However, a number of research questions remain, including (1) the optimal length and form of a signature in a given literature; (2) methods for creating a signature directly from statistical analyses of large samples of text; (3) the best way to map large numbers of related low-frequency words (needed for precision) into the same marker positions; (4) the merit of precomputing a ranked list of, say, 500 other sections that are most similar to each section (at 4 bytes per pointer, this would increase the storage requirements by 2,000 bytes per section); (5) the best way to eliminate false positives, since signature file searches are likely to produce more false positives than literal word searches, which produce false negatives in full-text retrieval.
Four of these questions involve ways to improve full-text retrieval through text analysis and transformation, rather than refinements in the search program itself. Better full-text retrieval begins with better information from the text file.
2. WORD-LEVEL PROBLEMS IN RETRIEVAL
Some retrieval problems result from faulty database design, such as leaving key fields unin-dexed. Some problems result from an awkward fit between database and retrieval system, such as requiring dashes or underscores as phrase-binders. Other problems are caused by mysterious search syntax, such as searching a phrase like New York City with proximity operators: New (n1) York (n1) City.
However, words themselves are the most common and intransigent source of retrieval pro-blems. Word-level problems include error, selection uncertainty, meaning ambiguity, and morpho-logical scatter.
Error. Carmen Sandiego, the master of computer
crime, was reportedly sighted in several maga-zines including Media
& Methods, CD-ROM Professional, and Booklist. A search in
the Magazine Index determined that the person seen was not Carmen Sandiego
but Carmen San Diego. However, other evidence suggests that Carmen San
Diego is merely the criminal's nom de database. This ruse works
with computers, since a search on Sandiego will not retrieve San
Diego.
Figure 1. Where in the File is Carmen Sandiego?
_______________________________________________________________________________
Where in the World is Carmen San Diego? Deluxe Version 1.0. Shankar, Guss; CD-ROM Professional, Jan 1, 1993, v6, n1, p145.
Where in the World is Carmen San Diego? Markuson, Carolyn; Booklist, May 15, 1993, v89, n18, p1709.
Where in Time is Carmen Sandiego? Software showcase. White, Beth; Teaching and Computers, May 1, 1990, v7, n6, p53.
Carmen Sandiego and her new gang wreak havoc with America's past. Ellison, Carol; PC Magazine, Oct 15, 1991, v10, n17, p502.
Where in America's Past is Carmen Sandiego? Pearlstein, Joanna; Macworld, March 1, 1993, v10, n3, p176.
All types of information, even the word information itself (see Figure 2), are subject to error in electronic databases. The majority of new databases are now full-text rather than bibliographic Full-text information enters a database directly from an author, editor, or data-conversion bureau. This vastly increases the amount of information in a database that information specialists such as abstracters and indexers do not control and may never see.
Abstracters and indexers are fallible too, as evidenced by the typographical errors in titles and abstracts shown in Figure 2 and the case of Stephen E. Robertson or Robinson shown in Figure 3.
Figure 3. A Reply to Robertson or Robinson?
_______________________________________________________________________________
Replies to Stephen E. Robinson's article on the role of fuzzy set theory in information science (Journal of the American Society for Information Science; v29, n6, Nov 1978), particularly with regard to Robinson's discussions of uncertainty, min/max connectives, and relevance. (FM)
Source: ERIC on DIALOG, September 1993
Spelling variants such as behaviour/behavior and haemodynamic/hemodynamic between Bri-tish and American English cannot be counted as errors, but they affect retrieval in the same way. The popular index expansions (online) and "wordwheels" (CD-ROM) of index terms would not show haemodynamic and hemodynamic in close proximity. For example, they are separated by hundreds of words in the MEDLINE index. Searchers must remember to search on variant spell-ings, or the search software must be smart enough to retrieve variant spellings when any one of the spellings is entered by a searcher.
Selection uncertainty. When searchers enter cancer rather than neoplasm or vice versa in an unfamiliar database, they are hoping to match the vocabulary of the index. Of course they could enter both at the same time, but it would be exhausting to elaborate every query with additional words that might match the index vocabulary.
Cancer and neoplasm are a well-known pair of search words in MEDLINE, because cancer dominates in the abstract field (105,005 occurrences vs. 20,569 occurrences for neoplasm) while neoplasm dominates in the descriptor field (688,734 occurrences vs. only 3,001 occurrences for cancer). However, in DIALOG's MEDTEXT file of full-text journals, cancer outranks neoplasm in both the text field (8,836 occurrences vs. 4,104) and the descriptor field (2,933 occurrences vs. 787). The eight possible NOT searches (cancer NOT neoplasm vs. neoplasm NOT cancer in abstract or text vs. descriptor fields in MEDLINE vs. MEDTEXT) yield a total of 790,589 records in which only one of the two words occurs in the given field. This is an inflated total because the NOT search was performed separately in two fields per record, but the true total cannot be less than 395,294 records in which using the wrong word in a field-specific search would result in a false negative. (Source: MEDLINE and MEDTEXT on DIALOG, September 1993).
In the Compact Innal Agricultural Research Library, a 17 CD-ROM project that Knowledge Access Inc. recently completed for the World Bank, the usual problem of encompassing synonyms in a search is compounded by more than 20 languages in which the research documents were written. Even British English and American English differ significantly. Reports on the same topic from different sides of the Atlantic might be entitled "Intercropping of Ground Nuts and Maize" or "Crop Rotation of Peanuts and Corn".
Meaning ambiguity. Some key search words in major databases are known for their meaning ambiguity. For example, nurse and nursing are difficult to use in MEDLINE. Often titles, ab-stracts, and descriptors must be scanned individually to resolve the meaning ambiguity of "to nurse, or nursing, the sick" vs. "to nurse, or nursing, an infant". Usually it is the second meaning that the searcher wants to exclude with a NOT search, but most of the words that might be used to exclude nursing infants would also create false negatives by excluding, for example, "nursing sick infants" unless the search has a completely different focus such as "nursing the elderly".
As thousands of searchers have concluded by now, AIDS is an unfortunately named disease. The common noun aids is ubiquitous in full-text files. Articles on the AIDS disease may not contain any particular word such as disease or HIV that the searcher can combine with AIDS in an AND search to exclude the common noun references. Figure 4 shows the pattern of co-occurrences involving AIDS and related words. It also shows several references from the residual set in which AIDS is not accompanied in the title or text by any of the related words.
Morphological scatter. The different words
that a wordstem or morpheme can generate are limited only by the
number of prefixes, suffixes, gerunds, participles, and other derivatives
that have a recognized meaning. Cancer can become cancerous
and then precancerous. Neoplasm can become neoplastic
and then antineoplastic. It is easy for the human eye to see the
common morpheme contained in each of these forms but much harder for the
computer. Rules and dictionaries are used to generate additional index
postings -- for example, posting antineoplastic to neoplasm
as well as its own location. Some search programs can remove prefixes and
suffixes from query words to search on the wordstem.
3. FULL-TEXT PROCESSING PROCEDURES AND RETRIEVAL STRATEGIES
The usability of a full-text CD-ROM collection is a joint product of (1) the text processing analysis and transformation that takes place during CD-ROM production and (2) the search program features that utilize the text processing output.
Text processing occurs at both the section level and the word level. In each case the original file is transformed or an auxiliary file is created to transfer new information about the file to the search program. At the section level, some combination of the following steps takes place:
Tagging sections with respect to the fields in which they can be searched, if field searching is enabled by the search program. A section may be part of the forematter, main text, reference list, appendix, footnotes, captions, etc. It is often helpful to search for a word or phrase only when it is known to occur in the main text, not in a reference list or footnote.
Linking sections to each other for hypertext retrieval by placing origin and destination links in the file or storing the origin and destination addresses in an auxiliary file.
Profiling sections for homologous retrieval
by computing their signatures or other encompassing descriptions such as
ranked lists of their most common words other than stopwords. This is a
non-existent or new area of text processing for most CD-ROM producers,
largely because search program features are still being developed to use
profiles in homologous retrieval.

Delineating words in the character stream that also contains nonwords. Punctua-tion, parentheses, brackets, apostrophes, and other elements of nonwords are recognized and processed according to rules. For example, an apostrophe will probably cause an entire word such as Murphy's to be indexed as well as the left segment Murphy.
Rectifying or conforming words prior to indexing. Spelling errors and varian-ces are resolved insofar as processing time permits.
Augmenting words with synonyms or distinguishing qualifiers. The first activity of adding synonyms may also take place at the time of a search. The second activity of disambiguation is an important step prior to indexing. For example, "faintness" in "symptoms of faintness" and "faintness of the symptoms" would ideally be posted in different index locations such as faintness (syncope) and faintness (indistinctness).
Indexing words by assigning them to locations in an auxiliary index file. What is actually stored in conjunction with each word in the auxiliary file are the addresses of its occurrences in the main text file. Each address belongs to a section, and each section becomes a retrieval "hit" for the word. The precise address is also needed in proximity searching, which checks the number of intervening words at each joint occurrence of search words in a query such as full-text NEAR CD-ROM WITHIN 10.
Search programs differ in appearance and in their input conventions, such as entering a question in natural language, entering a search command in correct syntax, filling in a search template, or choosing words from word lists. However, in the actual conduct of a search, most search programs support the following retrieval strategies:
Phrase search, exact match.
Partial word ("wildcard") search, left or right truncation, many possible matches.
Boolean AND-OR-NOT search, two or more words.
Proximity search, two words.
Relevance-ranked output, multiple word OR search, sections are ranked for output on the basis of how many search words they contain and the importance that the searcher places upon each search word.
Browsing the file via a table of contents.
The signature file concept. The compressed text representation known as a signature file was described two decades ago by Knuth (1973). A signature file is a surrogate of a text file, represent-ing attributes of the text file as succinctly as possible. Frequently the marker or presence of attribu-tes is mapped as a bit pattern, which is then packed into the words of a mainframe computer or the bytes of a personal computer. For example, the presence of eight attributes (words, categories, semantic clusters) in a text file can be packed into just one byte of storage, whereas the attributes themselves may use a hundred bytes of storage.
In addition to storage efficiency, a signature lends itself to two uses. A query involving one or more attributes can be expressed as "on" bits in a query signature in the same positions that are assigned to those attributes in the text file signature. The binary positions of the query signature and each text file signature can be pattern-matched in order to rank the similarity of each text file to the query. The result is a ranked retrieval of text files for inspection.
Pattern-matching can also be performed between all pairs of text file signatures, yielding a measure of text file similarity. This seems to be the most practical way to establish connections among related text files (documents or sections) other than editorial markup. If the similarity scores prove to be specific and accurate, then it is also the most practical basis for homologous retrieval.
Designing the signature. Like hypertext markup by an editor, a signature is meant to be a knowledgeable guess about the text attributes that searchers are interested in. Since the signature is a reduced representation of the text, it captures only the particular attributes that its designer chooses to emphasize. Signature length or number of attributes represented is the principal determinant of relative precision, whereas a short signature can increase recall by clumping related concepts into a single element of the signature so that any one of them can trigger a retrieval.
The other dimension of signature design is the level of syntactic or semantic represen-tation that each marker in the signature signifies. Frequently words are the chosen level of repre-sentation (Bookstein and Klein, 1990; Kent, Sacks-Davis and Ramamohanarao, 1990; Wong and Lee, 1990).
Markers can be more inclusive than individual words. Statistical analysis or human judgment may identify a cluster of words that should be assigned to the same marker. Then, when any word from the cluster appears in text section, that marker is turned on in the section signature. When that marker is on in another section signature because of any word from the cluster, the match is made.
Working assumptions. A full-text CD-ROM collection contains one content unit every 10,000 bytes or four pages on the average. This is typically the amount of text under one heading in a journal article or book chapter. It is believed that the discussion within each content unit, or section, is semantically interrelated, while the discussion in two separate sections may not be related, hence the importance of bounding the text by headings wherever possible.
Signature files can be created from many attributes of documents, even extrinsic attributes such as date and country of publication, document length, authorship, etc. However, in a full-text database the only common denominator across diverse content units is the text itself. We assume that signature files of full-text databases are generated from natural text words.
There is a role for stemming in generating signature files from text (see also Harman, 1991) but not necessarily a role for parsing at this time. Stemming allows variant forms to be matched. For example, analysis, analyses, analyze, analyzes, analyzed, analyzing, analytic, analyst, and analysts all match the wordstem analy. Left unstemmed, they would fail to match each other and would also expand the signature file without adding discrimination.
Only substantive words need to be considered in constructing a signature file for a full-text database. Across millions of words in full-text databases, we have found that the 100 most common words, which occur about equally in all sections, account for about 50% of all word occurrences. When they are deleted, about half of the processing time in creating a signature file can be saved.
Figure 5 illustrates differences in mapping words to a signature file vs an index.
5. THE TEST DATABASE
In order to use MEDLINE records from our own electronic products and save the expense of downloading or purchasing other records, we chose to focus on five health care topics that do overlap to some degree but should be discriminable with a good signature algorithm. They were: (1) health promotion and disease prevention; (2) patient care from the nursing perspective; (3) cancer treatment; (4) medical science -- a search emphasizing the "-ologies"; (5) health care policy and planning. In discussions and tables that follow, these five topics are designated as PRO, PAT, CAN, SCI, and POL.
Three separately analyzed parts of each record are the title (TI), abstract (AB), and descriptors (DE). Figure 6 illustrates these fields in a typical MEDLINE record. Topic-field acronyms are used to label the tables. For example, titles in health promotion articles are referred to as PRO-TI.
Number of records and different descriptors in each subfile. The five-topic database for signature file development contains 36,573 records. The smallest subfile is PRO, with 672 records. It had already been drawn for reference purposes and contains only post-1990 records. With diverse subtopics in addition to the health promotion focus, it contains 1,698 different descriptors. That is, there are more than twice as many different descriptors as there are records.
PAT contains 8,648 records with 5,761 different descriptors. CAN has 6,178 records with 6,360 different descriptors. SCI is substantially larger, based on searching MEDLINE records for descriptor references to medical research specialties; it contains 9,166 records with 13,696 different descriptors. The largest subfile of all is POL with 11,909 records but only 5,303 different descrip-tors, the second smallest number.
In each subfile the number of different descriptors is regarded as an indication of the probable size of a signature file for that subfile. For example, it should take a larger signature to represent the SCI subfile with 13,696 different descriptors than the POL subfile with 5,303 different descriptors, even though there are more records in the latter.
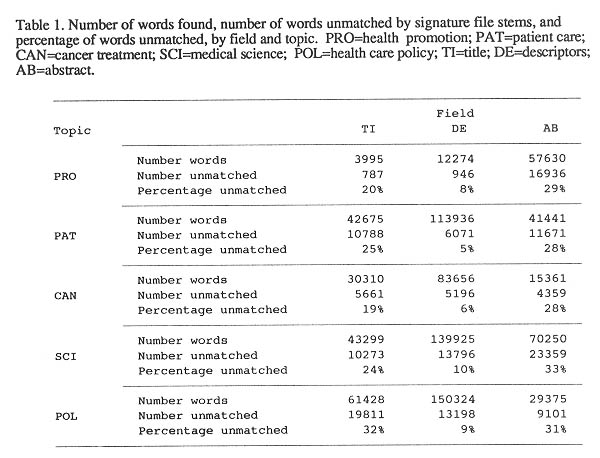
The total substantive word count was 895,879 after stopwords were removed (90 word list). Figure 7 shows partial counts for the TI, DE, and AB fields in three subfiles (PRO, PAT, and CAN).
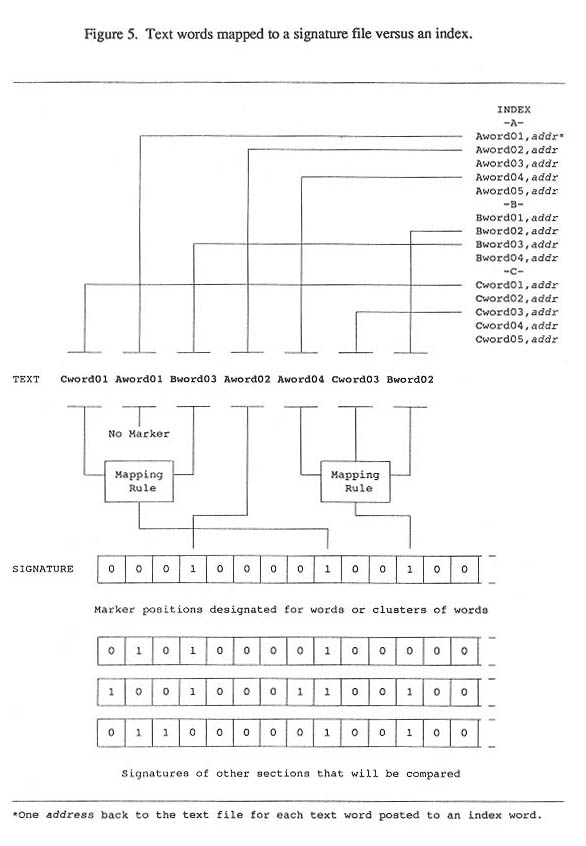
Figure 6. Example of typical MEDLINE record showing fields that were used to derive
and test the signature files. (Other fields except citation deleted).
_______________________________________________________________________________
AU: Windsor RA; Li CQ; Lowe JB; Perkins LL; Ershoff D; Glynn T
JN: Am J Public Health; 83 (2) p173-8, 1993
AB: The smoking prevalence rate among adult women and pregnant women has decreased only 0.3 to 0.5% per year since 1969. Without a nationwide dissemination of efficacious smoking cessation methods based on these trends, by the year 2000 the smoking prevalence among pregnant women will be approximately 18%. This estimate is well above the US Department of Health and Human Services Year 2000 Objective of 10%. The US dissemination of tested smoking cessation methods could help an additional 12,900 to 155,000 pregnant smokers annually and 600,000 to 1,481,000 cumulatively to quit smoking during the 1990s. Dissemination could help achieve 31 to 78% of the Year 2000 Objectives for pregnancy smoking prevalence. (With dissemination, at best a 15% smoking prevalence during pregnancy, rather than the 10% objective, is likely to be observed.) Our results confirm a well-documented need for a national campaign to disseminate smoking cessation methods.
DE: Health Policy; Health Promotion; Information Services; Pregnancy; Smoking-Epidemiology-EP; Smoking Cessation; Adult; Cohort Studies; Evaluation Studies; Prevalence; United States-Epidemiology-EP
Distribution of descriptors. The large number of descriptors (223,504 total postings, or an average of 6.1 descriptors for each of the 36,573 records) belies the fact that most descriptors occur only once or a few times. Therefore in a signature file they would be more useful in ensur-ing precision than recall..
In fact, only 1,110 descriptors occur 5 or more times. Of these, 827 occur in only one subfile such as PRO, which is a first test of distinctiveness. At the other extreme, only 26 occur in all five subfiles (62 in 4 or more subfiles, 122 in 3 or more subfiles, and 283 in 2 or more subfiles).
Descriptor Clustering is an alternative to the task of winnowing down nearly a million full-text words to choose markers for the signature file. Cluster analysis should show the latent structure underlying the large number of occurrences. Theoretically, the latent structure can be used to identi-fy the marker positions on the signature. Further analysis of the descriptors and their counterpart words in the full-text file would generate rules whereby large numbers of different words would be assigned to a few hard-working marker positions. For example, one marker could encompass many references to minority populations; another could encompass many references to hypertension, etc.
Unfortunately, the MeSH system has a species-differentia
logic of construction (eg, "Adju-vants, Immunologic - Therapeutic Use").
It is what factor analysts call bi-factored. A relatively small number
of descriptors deal with disease condition, organ group, age, sex, ethnicity,
locale, and function with respect to the health care system (eg, nursing
care, patient compliance). Most of the other MeSH words are quite specific
and lack the frequency that cluster analysis favors. There-fore cluster
analysis does not assign them strongly to clusters, and they do not acquire
a marker position in the signature file. Figure 8 shows the generality
that characterized the cluster analyses. Peat and Willett (1991) reached
similar conclusions about the limited value of word co-occurrence data
when used in the automatic elaboration of search queries.

Figure 8. Examples from descriptor clustering. Clustered descriptors and average links per pair.


Marking Signature Positions with Stemmed Full-Text Words. Full-text words have a wider range of types and occurrences than descriptors, offering more possibilities to mark the signa-ture positions. The problem with full-text language is the anarchy of semantically related forms that occur naturally in syntax in different syntactic positions. Before the computer can tally multiple occurrences of the same ameaning unit, it has to overlook differences in their forms. This is the province of stemming.
The frequency distribution of all full-text words is extremely skewed with a modal occurrence of one. Low-frequency words are not of value in a signature unless several can be grouped into one marker position.
In order to develop a signature based on full-text words, all words in the 36,573 records, including those extracted from the descriptor field, were aggregated, sorted, deduplicated, and grouped into families of wordstems.
Less-frequent words were held in abeyance according to the rule of marker efficiency, and the first signature comprised 864 wordstems (or, hereafter, simply "words"). Three iterations later, after leftover lists were compiled by running the signature against the 15 subfiles, the signature used for most analyses comprised 1265 words.
The degree to which the 1265-word signature accounted for all substantive words in the 15 subfiles is shown in Table 1. The percentage of unmatched words ranged from less than 10% in the
Figure 9. Descriptors from the CAN-DE subfile.
DE field to more than 30% in the AB field. The signature
accounts for the contents of the DE field more fully than the contents
of the AB field, probably because the AB field has a less restricted vocabulary
and may cover a wider range of topics. A low percentage of unmatched words
in a subfile means that the signature has represents the contents of the
subfile to a high degree. If all words match between text and signature,
then the subfile is fully represented by the signature. If few words match,
then the signature will seldom retrieve the subfile because it does not
have enough positive evidence to do so.
6. VARIANCE ANALYSES
Using variances to measure discrimination. For discrimination purposes an ideal marker will occur consistently in every relevant section and not at all in other sections. That is, it will have high variance across topics, with low variance attributable to other factors such as type of document.
There are two other variance outcomes. First, a marker may occur equally in all sections. If function words such as the were allowed to be markers, they would have low variance across sections. Second, a marker may have high variance on dimensions other than topic. For example, words like age are built into the phrase structure of MeSH and have high occurrences in the DE field, but in main text authors are likely to specify age ranges such as "patients over 65".
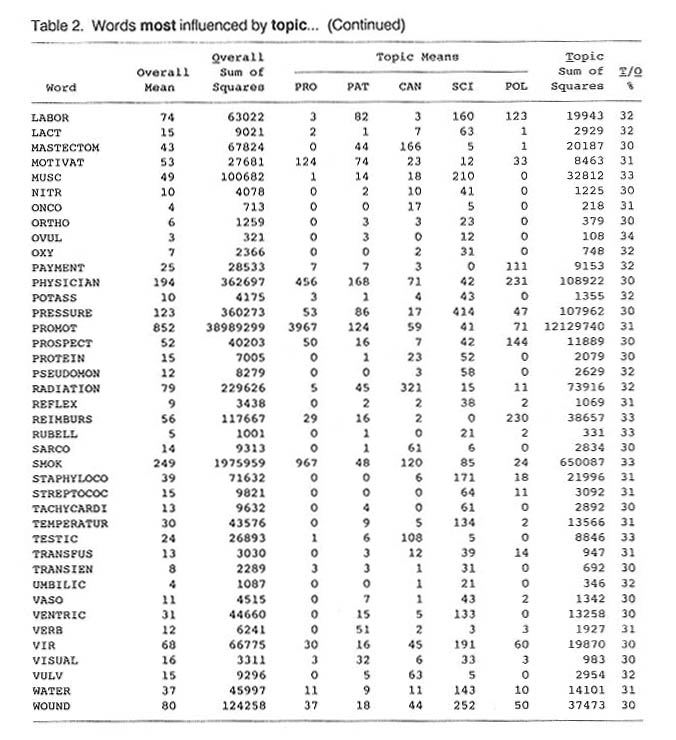
Analyses of variance were conducted by topic and by field to determine which markers provided the best discrimination across the five subfiles and which were most contaminated by field variance. Results of the analysis by topic are shown in Table 2. Some effects of field variance are shown in Table 3.
Table 2. MEDLINE words whose frequency is most influenced
by the topic that they address. Frequencies per 100,000 words, excluding
stop words. PRO=health promotion; PAT=patient care; CAN=cancer treatment;
SCI=medical science; POL=health care policy
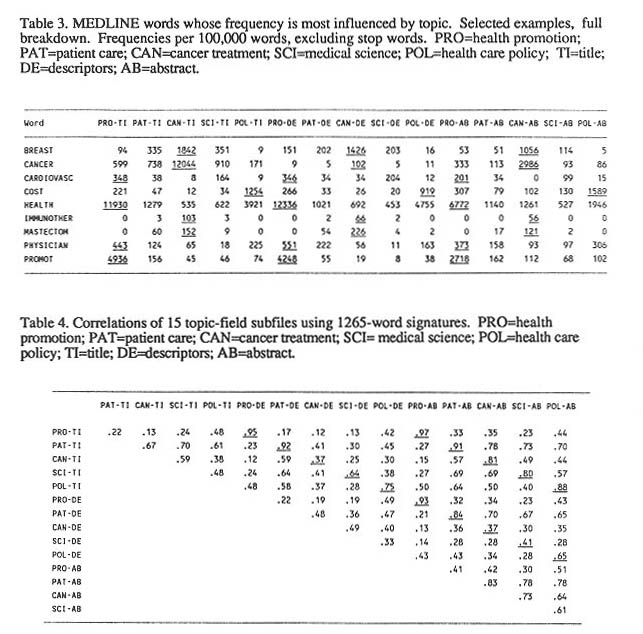
Discrimination Tests and Analyses. Correlations
were computed among the 15 signatures generated by the subfiles. The correlations
are biased by the non-normal distributions of markers within each signature,
but the bias is probably consistent across signature pairs because of their
similar distributions. The correlation results shown in Table 4 are encouraging
but not yet adequate. In 13 of the 15 subfiles, the highest correlation
would retrieve a correct related file.
Estimating the discrimination coefficients. To analyze the discrimination power of a signature, we must compare its same-topic correlations with all of the other correlations that it enters into. Ideally, the other correlations are zero, indicating that topics are the only source of variance in the correlation matrix and that the topics do not overlap in content (ie, correlate positively because of shared markers).
The 105-cell matrix shown in Table 4 contains 15 same-topic correlations and 80 other correlations that have non-zero values for at least three possible reasons: (1) the topics overlap in content, hence share some markers; (2) idiosyncratic field vocabularies affect signatures across topics; (3) other sources of variance are at work in the matrix.
The 15 same-topic correlations have a mean value
of .75. The 80 hetero-topic correlations have a mean value of .43. This
is the average "background noise" in the matrix. One heuristic estimate
of a discrimination coefficient would be:
or the square root of topic covariance minus extraneous covariance.
This contrived discrimination coefficient is neither large nor small in itself, but it can be com-pared with discrimination coefficients from other signatures and other databases.
We can use the same approach to quantify the performance
of a signature with respect to one subfile. For example, the PRO-TI subfile
is represented by 14 correlations in the first row of Table 9. Twelve of
these are hetero-topic correlations with a mean value of .27. Two are same-topic
correlations with a mean value of .96. The signature file's discrimination
power with respect to the PRO-TI subfile would be:
If PRO-TI were the originating section for homologous retrieval, the 1265-word signature would have a wide margin of discrimination between true positives and false positives.
Conversely, the CAN-DE subfile doesn't mesh with
this signature. Its 12 hetero-topic correlations have a mean value of .33,
while its 2 same-topic correlations have a mean value of only .37, with
the result:
Further analysis of the signature's performance with
respect to CAN-DE points again to the famous rift between cancer
and neoplasm. Neoplas? (stemmed word) has only 28% as many
occurrences as cancer? (stemmed word) in MEDLINE titles and abstracts,
while cancer? has fewer than 1% as many occurrences as neoplas?
in the MeSH descriptor field (see Table 3).
7. DIRECTIONS FOR FURTHER DEVELOPMENT
Important research and development questions remain to be answered, including:
1. What is an optimal length and form of a signature for health care literature? The health care signature will continue to be developed via tests and analyses so that it can finally serve as a satisfactory model for more automated development of signatures. A signature with truly broad coverage may need to be thousands of bytes long. Therefore it may also need to be hierarchical, with a short upper layer -- its own signature -- for high recall on a first pass and a long lower layer for high precision on a second pass.
2. To what extent can a topic-spanning signature be developed directly from large samples of text? The distant goal is to input large files with unknown topics and characteristics, receiving as output the set of signatures that represent every section (defined, for example, as the text that follows every major heading in journal articles and book chapters). At first it will be necessary to monitor each step with human judgment. Can human judgment be incorporated in smarter algorithms that ultimately run themselves?
3. What is the best way to map large numbers of related low-frequency words (needed for precision) into the same marker positions? The diffuseness of full-text results partly from the large number of nearly equivalent terms that are paradigmatic rather than syntagmatic associates. That is, they tend to occur in the same context "slots" rather than follow each other in context. Therefore their co-occurrences are low and conventional cluster analysis will not bring them together. One solution may involve computing the "context signatures" that such words share.
4. If section-to-section searching is the goal rather than query-to-section search-ing, should signature similarity be precomputed for faster access? We want to inves-tigate the feasibility of storing ranked lists of, say, 500 similar signatures for every signature at the time of text processing. The searcher is not interested in 500 other sections, but this set forms the domain for narrowing on other criteria.
5. Since signature file searches are likely to
produce more false positives than literal word searches (which produce
false negatives in full-text), how can homo-logous retrieval combine with
other searching strategies to eliminate the false positives? The precision
needed to eliminate most false positives would require long signatures
with greater storage requirements and longer comparison time. Instead,
the searcher should be provided with tools for narrowing the retrieved
set on other criteria. At this point, should the search simply revert to
efficient, literal Boolean ANDing, or should the searcher click on some
words in the retrieved output to launch another round of homologous retrieval
in which those words receive a higher weight, to be set at the searcher's
discretion?
REFERENCES
Bookstein, A. & Klein, S.T., "Using bitmaps for medium sized information retrieval systems," Information Processing and Management, 26 (4): 525-533 (1990).
Harman, D. "How effective is suffixing?" Journal of the American Society for Information Science, 42 (1): 7-15 (1991).
Kent, A.; Sacks-Davis, R. & Ramamohanarao, K., "A signature file scheme based on multiple organizations for indexing very large databases," Journal of the American Society for Information Science, 41 (7): 508-534 (1991).
Knuth, D.E. The Art of Computer Programming. Vol 3: Sorting and Searching. Reading, MA: Addison-Wesley, 1973.
Peat, H.J. & Willett, P., "The limitations of term co-occurrence data for query expansion in document retrieval systems," Journal of the American Society for Information Science, 42 (5): 378-383 (1991).
Wong, W. & Lee, D.L., "Signature file methods for implementing a ranking strategy," Information Processing and Management, 26 (5): 641-653 (1990).