Marjorie M.K. Hlava
Access Innovations, Inc.
Albuquerque, NM 87198-8640, USA
Richard Hainebach
EPMS bv-Ellis Publications
The Netherlands
E-mail: mhlava@nicem.com
The legislative process of the European Union produces thousands of documents in the nine official languages each year. The European Parliament is responsible both for producing some of these documents as well as for monitoring them. To this end, the European Parliament has developed the EPOQUE database, which is intellectually indexed by the multilingual EUROVOC thesaurus. The intellectual indexing process is labor-intensive, time-consuming and, therefore, expensive. Furthermore, it has been found that the indexing of the documents is not always consistent.
In 1992, the European Parliament published a Call for Tender for the design, construction, operation, and assessment of a pilot expert system for the intelligent automatic, or assisted indexing, of European Parliament documents, using as its base the existing multilingual European Parliament thesaurus (EUROVOC). The contract for the English language documents was finally awarded in 1993 to EPMS bv, located in Maastricht, whose proposal was based on the use of the machine-aided indexing (MAI) software developed by Access Innovations, Inc. of Albuquerque, NM. The project began in mid-1994.
2. THE MAI ENGINE
Access Innovations' MAI has already been described by Hlava (1992). The MAI's main feature is that it produces proposed terms from a knowledge base or several knowledge bases. The knowledge base itself is a database of text recognition rules.
There are three major components of a rule. These can be seen as the fields in the rules database shown and defined here.
CONDITIONS, or logic, are instructions to the MAI engine qualifying, accepting, or rejecting assignment of an indexing term based on Boolean logic, relevance marking, and other logic. Right- and left-hand truncation is used in the word standardization section of the Rule Builder.
SUGGESTED TERM, or index term, is the approved indexing term to be assigned if the logic is true.
MATCH RULE
//TEXT: land productivity
USE land productivity
SYNONYM RULE
//TEXT: GNP
USE Gross National Product
Complex rules use one or more conditions.
If a key word or phrase is matched, then the MAI may assign one, many,
or no suggested terms based on rule logic. There are three condition types:
proximity, location, and format. This is shown in more detail below.
PROXIMITY Conditions
near - within 3 words before or after in the same sentence
with - in same sentence
mentions - in same field, normally abstract or text
LOCATION Conditions (can be set by the rule builder)
in title - if matched text is in title
in text - if matched text is in abstract or text
begin sentence - if matched text is located at beginning of sentence
end sentence - If match text is located at end of sentence
FORMAT Conditions
all caps - if text is all caps
initial caps - if matched text begins with a capital letter
IF (all caps)
USE research policy
USE Community programme
ENDIF
IF (near "Technology" AND with "Development")
USE Community programme
USE development aid
ENDIF
IF (near "Technology" AND with "Environmental Protection")
USE Community programme
ENDIF
USE common regional policy
USE technology transfer
ENDIF
IF (near "Technology" AND with "Strategic Analysis")
USE Community programme
ENDIF
Performance of the MAI is normally measured against human-indexing by measuring:
HITS - when the MAI engine generates an indexing term identical to an index term which would have been assigned by a human indexer;4. PROCEDURES AND THEORY IN BUILDING THE RULES BASE FOR THE MAIMISSES - when the MAI engine fails to generate an indexing term which would have been assigned by a human indexer; and
NOISE - i.e., when the MAI engine generates an indexing term which is genuinely incorrect, out of context, or illogical. (In the case of EPOQUE, this should not be confused with terms generated by the MAI but not selected by the human indexer.)
If MAI is to be a successful tool, it is important to build a rules database that will produce relevant and consistent index terms. General rule-building in such a project is the utilization of the existing thesaurus, i.e., number of lead terms, number and quality of synonyms, the currency of the thesaurus, etc., as well as a working knowledge of the types of source documents to be indexed. It is important to analyze the documents by the types of language and vocabulary used in the documents themselves, by the structure of each document, i.e., whether it is fielded, whether it contains an abstract, whether it is full text.
The basis of all indexing in EPOQUE, is EUROVOC, a multilingual (nine-languages), hierarchical thesaurus. It includes 5,359 descriptors. The ratio between descriptors and non-descriptors is extremely low when compared with other thesauri. The thesaurus is characterized by:
terms or phrases, which are frequently used in the text but don't necessarily have to be indexed by that term. Examples are words like "income", "financing", "expert", "economy", "discount", "decision", "culture", and "management".
other terms or phrases which could have double meanings. For instance, "account" (as in balance sheets) is often used in the text as 'take into account'; "lead" (as in the mineral) is often used as a verb in the text; AIDS (as in "Acquired Immune Deficiency Syndrome") may be confused with financial aid or state aid; and, "advance" (as in budget) is often used a verb.
abbreviations or acronyms which could have a double-meaning,
for example, WHO, BIT, CART.
For the initial period, 274 full-text documents complete with human indexing were delivered to EPMS to be used to be used as a basis for rule-building.
The document types are as follows.
COM Finals (Commission proposals)
Technical Sheets
Parliamentary Questions & Answers
Resolutions from the Parliament
Although a document focused on a specific subject it also may have include annexes or references to unrelated subjects. Certain words and phrases such as "European Parliament" or "Commission of the European Communities" were always present, making them meaningless as significant text strings. On the other hand, there were many legal citations, for example, "Council Directive 79/112/EEC" or "Commission Regulation (EEC) 1408/71", which could be used to indicate the subject matter.
The human indexing provided with the documents did not always reflect all of the subject matter in the document. We found the quality of indexing to be better on the Parliamentary Questions and, therefore, decided to use this indexing as the initial
"standard set".
5. RULE BASE BUILDING AND TESTING
In order to build the rules database, the following steps were taken and completed by mid-September 1994.
b. The source documents also were converted and brought into an INMAGIC database.
c. We started to add our own "synonyms to the EUROVOC thesaurus" in a separate field so as not to confuse them with the "official EUROVOC non-descriptors". This was accomplished by examining other collections of EC vocabularies in our possession as well as the language used in legislative titles, which had been indexed already using EUROVOC.
2). EUROVOC non-descriptors as TEXT strings
3). ELLIS Publications synonyms to EUROVOC
4). modification of 1) + 2) + 3) to fit the MAI engine (identification of the greater-than- four-word phrases and transferal of them to the complex rule stage)
5). suggested terms (created by running the data produced in steps 1). through 4). above against the sample)
e. We ran the Parliamentary documents against this simple rules database and examined the results from the point of view of HITS, MISSES and NOISE. We parsed the EUROVOC compound terms, EUROVOC non-descriptors, and the ELLIS Publications synonyms.
f. Using the results of the above analysis, the editors began work on the complex rules using Boolean and proximity operators by deciding:
1). whether or not a descriptor should remain as a MAIN TEXT STRING. If yes, whether it should have associated complex conditions, and
2). whether or not a non-descriptor should remain
as a MAIN TEXT STRING. If yes, whether it should have associated complex
conditions.
h. A new MAI rules database was created by combining the following three separate files.
1). Descriptors from EUROVOC as MAIN TEXT STRINGS, which did not create noise,
2). Non-descriptors from EUROVOC as MAIN TEXT STRINGS, which did not create noise, and
3). Rules developed with complex conditions.
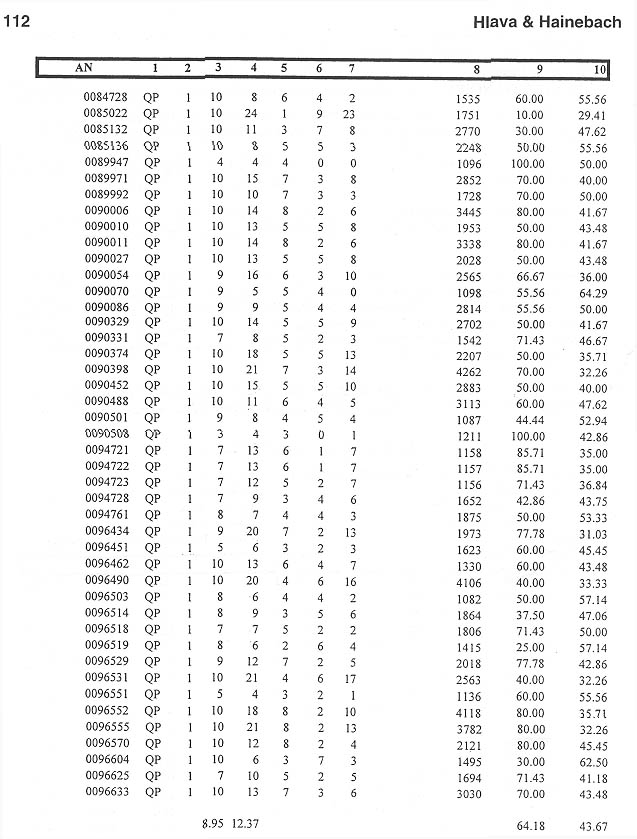
i. We then ran the Parliamentary Questions data files against the more sophisticated MAI rules database and analyzed the results for HITS, MISSES and NOISE. Based on the analysis, the rules were refined in order to achieve better results. This went through several cycles, enhancing the rules base each time. With the existing rules base we achieved the following result: 7 Hits, 2 Misses, 3 Noise/Consistency =3D 58%
NDOC: 0090070
TITLE:WRITTEN QUESTION No. 1501/92 by Detlev SAMLAND to the Commission. Staff management
HUMAN ALLOCATED
staff administration staff administration
administrative law European official
European official information bureau
Community institution Community institution
labour mobility capital city
EC servants administrative law
information bureau labour mobility
EC Commission loan
institutional cooperation EC servants
staff
2. Can the Commission state on what principle of administrative law the 'lending' of officials in this way is based and whether practices of this sort are to be viewed as a contribution to greater inter-institutional mobility?
3. Can the Commission provide further details of how many of its officials are on loan to other institutions in this way and whether their duties could otherwise be allocated to external staff?
Answer given by Mr. Cardoso e Cunha on behalf of the Commission (23 September 1992)
1. Yes.
2. The person concerned has been seconded on an ad hoc basis for personal reasons pending a transfer, which could be completed in the near future.
3. There are no other similar cases of secondment.
- - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - -
We then moved to the creation of rules based on the natural language occurrences in the source data. Our objective was to achieve a HIT rate of greater than 60% against the human indexing. We called this stage the MISS Analysis. We investigated the potential for additional rules by studying the text as well as more deeply analyzing the MISSES to see how, with additional rules building, we could have "caught" a term.
k. In order to take advantage of the legal citations, a separate rules database was created for the MAI and run against the document base.
l. We introduced restrictive rules to reduce the level of NOISE. This was done first to take the high level NOISE terms and remove them from the knowledge base as postable terms.
m. To restrict the data postings to the 20 terms per document that the Parliament requires, we added a relevance weighting system. To decrease the number of terms identified for the individual records we applied a relevance ranking algorithm based on the number of times a particular term was called for in each record. The top twenty terms then were accepted as those most relevant and all others deleted from the descriptor file.
n. In order to increase the number of HITS we reviewed all of the rules to determine which ones were too restrictive and then loosened them as appropriate in order to cast a broader net for descriptor terms.
o. Since the rule building policy was to increase
the HIT ratio and the lengthier documents tended to create more suggested
terms, if the number of human descriptors assigned to the document is low,
then more so-called NOISE is created. It would have been simple to eliminate
the high NOISE terms from the vocabulary to increase the ratios (shown
in Table 1.) Some of this NOISE is actually highly relevant indexing. Therefore,
we analyzed the relevant NOISE.
6. CROSS VALIDATION TECHNIQUES
We found that there were still too many HITS/NOISE as measured against the human indexing. This was because of the full-text nature of the documents.
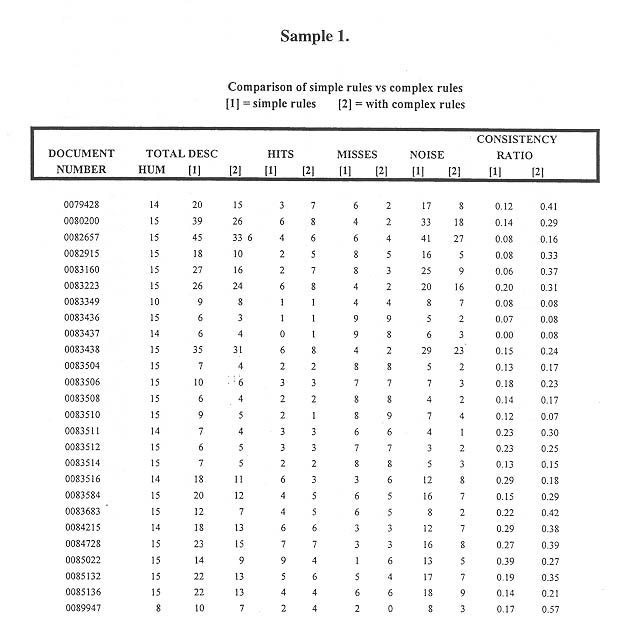
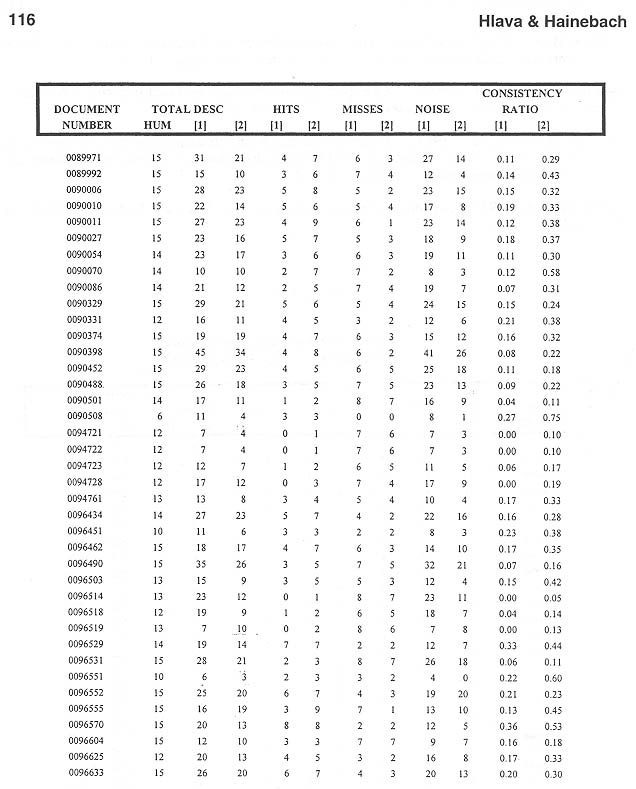
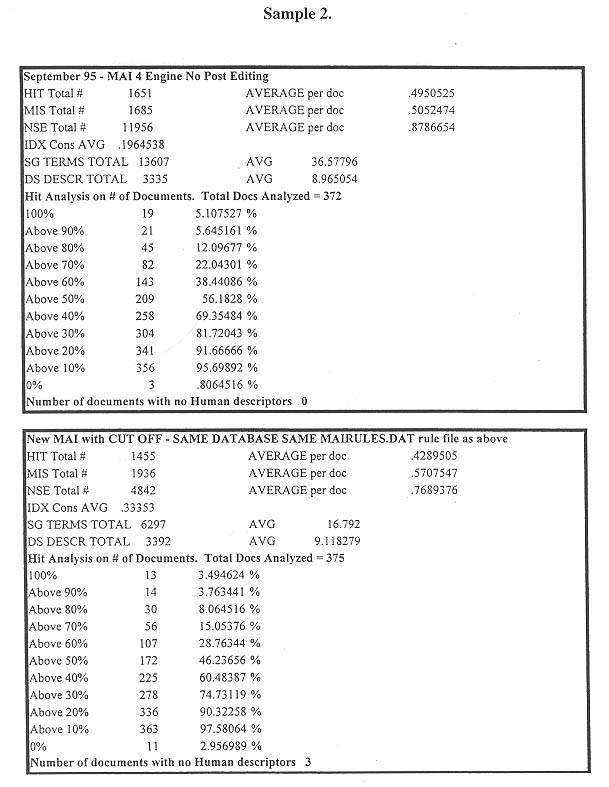
b. In order to test the validity of the MAI indexing against standard sets we ran the same rule base against three independently indexed sets of the same data and applied both the Bureau Van Dijk index (used by the EP evaluator) and the API HIT/MISS/NOISE ratios to see how each ranked against the others. (See Bibliography reference: Martinez, Clara, et al. ...) The results of these data comparisons are shown in Samples 3-5.
c. The three sets are based on the:
1). CATEL indexing - (Indexing of Office of Official Publications in Luxembourg),
2). EPOQUE indexing described above, and
3). Ellis Publications indexing of European laws.
The HIT ratio analysis for the test batches shows
the following:
Without cutoff 49.5 50.5 87.8
With cutoff 42.9 57.0 76.8
Second Test
Commission Documents 44.88 48.0
Technical Documents 49.06 68.0
Questions & Answers 63.23 43.0
EP Reports 38.52 75.0
EP Resolutions
38.75 44.0
The MAI increases the productivity of the general
indexing process. It also provides for more consistent indexing and more
depth. The creation of a standard set of documents to measure against was
not done in this project. But the cross validation shows clearly that without
any
human intervention the machine- aided indexing (MAI) does as well as the
human. Used in concert with human indexers as originally conceived, the
system can provide faster, more consistent, more economical, and better
quality indexing.
REFERENCES
Bureau van Dijk. (1992, February 27). Call for Tender for the Design, Construction, Operation, and Assessment of a Pilot Expert System for the Intelligent Automatic or Assisted Indexing, and Possibly Searching, of European Parliament Documents on the Basis of the Existing Multilingual European Parliament Thesaurus.
_________. (1995, June 1). Evaluation des Deux Pilotes D'Indexation Automatique: Methodes et Resultats.
_________. (1995, April 20). Evaluation des Operations Pilotes D'Indexation Automatique (Convention Specifique n. 52556).
_________. (1995, May 24). Evaluation des Operations Pilotes D'Indexation Automatique (Convention Specifique n. 52556).
_________. (1994, December 20). Evaluation of the Automatic Indexing Pilot Operations (Convention Specifique n. 52556).
_________. (1995, January 2). Evaluation of the Automatic Indexing Pilot Operations (Convention Specifique n. 52556).
Dillon, Martin and Ann S. Gray. (1983). "FASIT: A fully automatic syntactically based indexing system," Journal of the American Society for Information Science, 34 (2): 99-108.
Earl, Lois L. (1970). "Experiments and automatic extracting and indexing," Information Storage and Retrieval, 6: 313- 334.
Fidel, Raya. (1986). "Towards expert systems for the selection of search keys," Journal of the American Society for Information Science, 37 (1): 37- 44.
Field, B.J. (1975, December). "Towards automatic indexing: Automatic assignment of controlled-language indexing and classification from free indexing," Journal of Documentation, 31 (4): 246- 265.
Gillmore, Don. (1994, December 5). "Outline of proposed changes to MAI by funding group," Memorandum, Albuquerque: Access Innovations.
Gray, W.A. (1971). "Computer assisted indexing," Information Storage and Retrieval, 7: 167- 174.
Hainebach, Richard. (1992, December). "European community databases: A subject analysis," Online Information, 92 (8-10): 509- 526.
_________. (1992). "Eurovoc Tender," Fax Transmission, Albuquerque: Access Innovations.
Hlava, Marjorie M.K. (1992). Machine-Aided Indexing (MAI) in a multilingual environment. In Proceedings of Online Information, 8-10 December 1992. Medford, NJ: Learned Information. pp. 297-300.
Humphrey, Susanne M. and Nancy E. Miller. (1987). "Knowledge-based indexing of the medical literature: The index aid project," Journal of the American Society for Information Science, 38 (3): 184- 196.
Klingbiel, Paul H. (1973). "Machine-aided indexing of technical literature," Information Storage and Retrieval, 9: 79-84.
Lucey, John and Irving Zarember. (1995, May 25). Review of the Methods Used in the Bureau van Dijk Report: Evaluation des Operations Pilotes d'Indexation Automatique. Freehold: Compatible Technologies Group.
Mahon, Barry. (1995, June/July). "The European Union and Electronic Databases: A lesson in interference?" Bulletin of the Society for Information Science, pp. 21- 24.
Martinez, Clara, et al. (1987). "An expert system for machine-aided indexing," Journal of Chemical Information in Computer Science, 27 (4): 158- 162.
McCain, Katherine W. (1989). "Descriptor and citation retrieval in the medical behavioral sciences literature: Retrieval overlaps and novelty distribution," Journal of the American Society for Information Science, 40 (2): 110- 114.
Tedd, Lucy A. (1984). An Introduction to Computer-Based
Library Systems. Suffolk: St. Edmundsbury Press.
0101180 - COM(92) 577
PROPOSAL from the Commission to the Council for a directive on the statistical surveys to be carried out on pig production
EPOQUE CATTLE MAI
statistics ------------ statistics
Community statistics Community statistics Community statistics
agricultural statistics ----------- agricultural statistics
swine swine swine
livestock livestock livestock
livestock farming ------------ livestock farming
slaughter of animals ------------ slaughter of animals
animal production animal production animal production
data collection ------------ ------------
EC committee ------------ ------------
Results: HITS
CATEL HUMAN vs EPOQUE HUMAN 100%
MAI vs CATEL HUMAN 100%
pigmeat Community policy
standing committee fattening
agricultural holding SOEC
EC proposal meat industry
EC opinion human nutrition
common agricultural policy implementation of Community law
competence of the Member States

